Last week, Seldon’s Director of Machine Learning, Alejandro Saucedo, gave a talk at KubeCon Europe – a flagship four-day conference hosted by the Cloud Native Computing Foundation. Alejandro considered how and why companies should approach benchmarking machine learning models, and ran through some practical case studies of benchmarking in action.
The event, which attracts adopters and technologists from leading open source and cloud native communities, provided a platform for Alejandro, who is also the chief scientist at the Institute for Ethical AI & Machine Learning, to showcase more than 10 years of expertise in software development experience.
While getting a machine learning model into production can initially seem like the final step of the development and deployment process, this often isn’t the case. Once placed in a live production environment, production models often find themselves diverging from the expectations held by teams during the development phase.
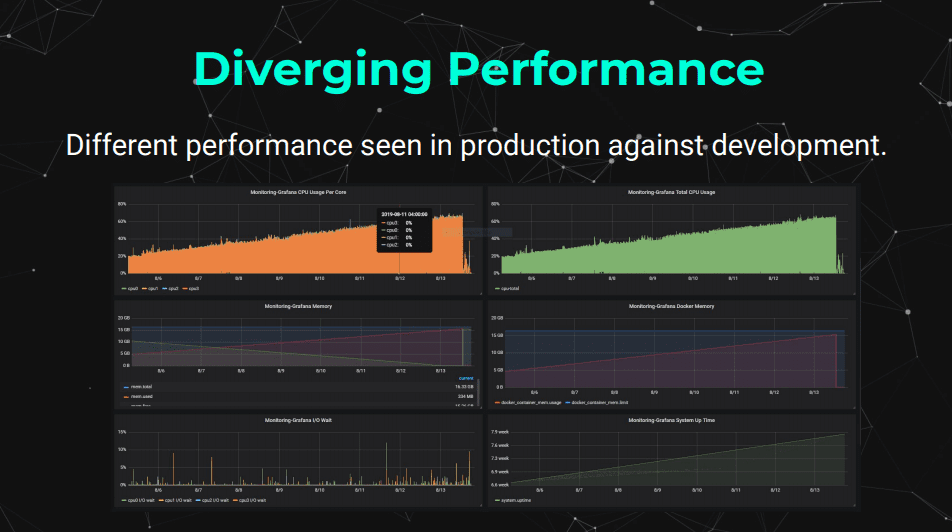
Unfortunately, many of us in the field are familiar with situations where a model’s performance falls off over the course of its deployment. Or, in some cases, a deployed model just outright stops working. All of these stories have a common foundation, regardless of whether they’re due to memory leaks, an insatiable growth in the demand for computing power, or some other unforeseen error: some unexpected nuances of a production model, as opposed to an in-development model, cause it to stall.
Alejandro discusses how benchmarking can prevent this.
When we speak of benchmarking, we’re referring to three types of activities. The first is performance testing, where we check how a system behaves and performs. The second is load testing, where we test a system’s response to increasing loads. The third is stress testing, where we test a system under extreme loads to assess how it performs (and fails).
And this is where benchmarking comes into play. Production machine learning models come in different shapes, sizes and flavours when deployed in cloud native infrastructure, and each of them will have different hardware and software requirements. Whether it’s RAM, CPU, GPU or Disk Space, there won’t be an optimal global configuration for all your models’ training and inference. Through benchmarking your infrastructure, you can understand whether it will be able to handle the demands of your production model for the long run.
In practice, organisations have six good reasons to ensure they benchmark their models appropriately, which Alejandro discusses:
- Firstly, it helps them obtain performance evaluations of new vs old models, with benchmarking providing an ideal ceteris paribus test of two models with the same use case on the same infrastructure.
- Secondly, benchmarking allows teams to assess the throughput for the processing of their models.
- Thirdly, benchmarking also allows teams to discover the latency per component within their deployment, which in turn allows them to identify which parts of their configuration may slow them down.
- Fourth, it allows teams to discover the resource limits of their infrastructure and allocate resources appropriately.
- Fifth, benchmarking can help teams in optimising the number of threads, workers, and replicas they assign to each model to maximise performance.
- Sixth, a benchmark can tell teams how a system will perform under load and stress, identifying the pain points to address.
In his talk, Alejandro explores the parameters that need to be accounted for during benchmarking; including latency, throughput, spikes, performance percentiles, and outliers. Furthermore, Alejandro also dives into a hands-on example, where he benchmarks a model across multiple parameters to identify optimal performance on specific hardware using Argo, Kubernetes and Seldon Core.
You can watch the full discussion from KubeCon below:
Interested in finding out more about Seldon? Get a demo here