Once you have a machine learning model in production that is providing benefit one of the next challenges you will meet is updating that model with the next version created by your data scientists. This challenges encompasses multiple questions:
- How do I know my new model is better than the existing model?
- How do I ensure new models pass key service level objectives (SLOs)?
- If I have many models in production how do I progress new versions for each in an automated manner to allow efficient updates without increasing the risk of deploying a new version of a model that is actually worse than the current running one?
With the latest release of Seldon Core we provide examples of how to update your running Seldon Core models using the Iter8 project.
Iter8 Integration for Progressive Rollouts
Iter8 is an open source project that makes it easy to optimize business metrics and validate SLOs when deploying Kubernetes applications including machine learning models through declarative cloud native progressive rollouts. We have integrated Seldon Core with iter8 to enable advanced use cases for experimentation utilizing objectives and rewards for candidate model selection. Iter8 also provides progressive rollout capabilities to automatically allow testing of candidate models and promoting them to the production model if they perform better without manual intervention.
In Seldon Core we provide two core examples which we will deep dive into below.
1. Seldon/Iter8 Experiment over a single Seldon Deployment.
The background to this example is you have a running Seldon Core model in production. The first step is to create an AB Test for the candidate model with an updated Seldon Deployment and run an Iter8 experiment to progressively rollout the candidate based on a set of core metrics. The architecture is shown below.
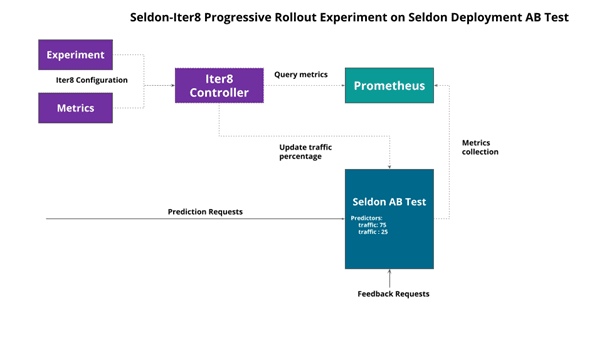
We begin by updating our default model to start an AB test as shown below, ensuring the candidate model has zero traffic initially.
apiVersion: v1 kind: Namespace metadata: name: ns-production --- apiVersion: machinelearning.seldon.io/v1 kind: SeldonDeployment metadata: name: iris namespace: ns-production spec: predictors: - name: baseline traffic: 100 graph: name: classifier modelUri: gs://seldon-models/sklearn/iris implementation: SKLEARN_SERVER - name: candidate traffic: 0 graph: name: classifier modelUri: gs://seldon-models/xgboost/iris implementation: XGBOOST_SERVER
|
Here we have the incumbent SKLearn model and a candidate XGBoost model to possibly replace it.
Next, we tell Iter8 the metrics it can use to help determin the best model and also ensure any model we do promote passes all required SLOs.
The list of metrics is shown below.
NAME TYPE DESCRIPTION 95th-percentile-tail-latency Gauge 95th percentile tail latency error-count Counter Number of error responses error-rate Gauge Fraction of requests with error responses mean-latency Gauge Mean latency request-count Counter Number of requests user-engagement Gauge Number of feedback requests |
It include 4 core SLOs (percentile-latency, error-count, error-rate, mean-latency) that we will use and a reward metric user-engagement we will use to determine which model is better at its task.
Iter8 provide a Kubernetes Metric custom resource to define the metrics. To illustrate this we show the error-count metric below.
apiVersion: iter8.tools/v2alpha2 kind: Metric metadata: name: error-count namespace: iter8-seldon spec: description: Number of error responses jqExpression: .data.result[0].value[1] | tonumber params: - name: query value: | sum(increase(seldon_api_executor_server_requests_seconds_count{code!='200',seldon_deployment_id='$sid',predictor_name='$predictor',kubernetes_namespace='$ns'}[${elapsedTime}s])) or on() vector(0) provider: prometheus type: Counter urlTemplate: http://seldon-core-analytics-prometheus-seldon.seldon-system/api/v1/query |
The metric allows us to define a prometheus expression to gather the raw data and how to extract the key value from the returned result in Prometheus as well as specifying the Prometheus endpoint to use. Other SLO metrics are defined in the same way.
Iter8 also provides other connectors for metrics including NewRelic, SysDig and ElasticSearch and allows one to handle the auth settings needed to connect to these providers.
We also define a user-engagement metric which counts the feedback messages sent to the model. Seldon Core provides a feedback API call to allow users to send validation on the predictions of their models. In this case we simply count the feedback API calls assuming each is a validation that a particular prediction succeeded some business user engagement criteria.
The metrics can then be used in experiments to define rewards to compare models and service level objectives models need to attain to be considered to be running successfully. This is shown below.
apiVersion: iter8.tools/v2alpha2 kind: Metric metadata: name: user-engagement namespace: iter8-seldon spec: description: Number of feedback requests jqExpression: .data.result[0].value[1] | tonumber params: - name: query value: | sum(increase(seldon_api_executor_server_requests_seconds_count{service='feedback',seldon_deployment_id='$sid',predictor_name='$predictor',kubernetes_namespace='$ns'}[${elapsedTime}s])) or on() vector(0) provider: prometheus type: Gauge urlTemplate: http://seldon-core-analytics-prometheus-seldon.seldon-system/api/v1/query |
Once the metrics are defined an experiment can be started as expressed by the Iter8 Experiment Custom Resource.
This has several key sections:
- Strategy: The type of experiment to run and actions to take on completion.
- Criteria: Key metrics for rewards and service objectives.
- Duration: How long to run the experiment.
- VersionInfo: Details of the various candidate models to compare.
To illustrate the parts we show snippets from this below. We want a progressive AB which will automatically promote the winning model:
strategy: testingPattern: A/B deploymentPattern: Progressive actions: finish: - task: common/exec with: cmd: /bin/bash args: [ "-c", "kubectl apply -f {{ .promote }}" ] |
We want our reward to be the user-engagement metric with highest value winning. We also set SLOs the model must meet based on the other defined metrics as shown below: mean latency at most 2 secs, 95th percentile latency at most 5 secs and error rate at most 1%.
rewards: # Business rewards - metric: iter8-seldon/user-engagement preferredDirection: High # maximize user engagement objectives: - metric: iter8-seldon/mean-latency upperLimit: 2000 - metric: iter8-seldon/95th-percentile-tail-latency upperLimit: 5000 - metric: iter8-seldon/error-rate upperLimit: "0.01" |
We define how long to run the experiment: 1 loop (the default) of 15 iterations with a 10 second gap between each evaluation:
duration: intervalSeconds: 10 iterationsPerLoop: 15 |
We also specify the Custom Resource paths for the traffic definitions in the Seldon Deployment so Iter8 can modify them as the experiment progresses.
versionInfo: # information about model versions used in this experiment baseline: name: iris-v1 weightObjRef: apiVersion: machinelearning.seldon.io/v1 kind: SeldonDeployment name: iris namespace: ns-production fieldPath: .spec.predictors[0].traffic variables: - name: ns value: ns-production - name: sid value: iris - name: predictor value: baseline - name: promote value: https://gist.githubusercontent.com/cliveseldon/acac9b7e6ba3c52cde556323be0fc776/raw/78781a1f5c86a6cc24c3c7e64e3df211bc083207/promote-v1.yaml candidates: - name: iris-v2 weightObjRef: apiVersion: machinelearning.seldon.io/v1 kind: SeldonDeployment name: iris namespace: ns-production fieldPath: .spec.predictors[1].traffic variables: - name: ns value: ns-production - name: sid value: iris - name: predictor value: candidate - name: promote value: https://gist.githubusercontent.com/cliveseldon/3766b9315a187aa2800422205832ad9b/raw/ba00718fcacb8014e826cc6410a8190aa19116d4/promote-v2.yaml |
The above definitions use variables which are injected into the metrics defined earlier allowing one to create a generic set of metrics that can be used across different experiments.
We can now start our experiment.
As the experiment progresses the status can be tracked with iter8 tool, iter8ctl:
****** Overview ****** Experiment name: quickstart-exp Experiment namespace: seldon Target: iris Testing pattern: A/B Deployment pattern: Progressive ****** Progress Summary ****** Experiment stage: Running Number of completed iterations: 6 ****** Winner Assessment ****** App versions in this experiment: [iris-v1 iris-v2] Winning version: iris-v2 Version recommended for promotion: iris-v2 ****** Objective Assessment ****** > Identifies whether or not the experiment objectives are satisfied by the most recently observed metrics values for each version. +-------------------------------------------+---------+---------+ | OBJECTIVE | IRIS-V1 | IRIS-V2 | +-------------------------------------------+---------+---------+ | iter8-seldon/mean-latency <= | true | true | | 2000.000 | | | +-------------------------------------------+---------+---------+ | iter8-seldon/95th-percentile-tail-latency | true | true | | <= 5000.000 | | | +-------------------------------------------+---------+---------+ | iter8-seldon/error-rate <= | true | true | | 0.010 | | | +-------------------------------------------+---------+---------+ ****** Metrics Assessment ****** > Most recently read values of experiment metrics for each version. +-------------------------------------------+---------+---------+ | METRIC | IRIS-V1 | IRIS-V2 | +-------------------------------------------+---------+---------+ | iter8-seldon/request-count | 5.256 | 1.655 | +-------------------------------------------+---------+---------+ | iter8-seldon/user-engagement | 49.867 | 68.240 | +-------------------------------------------+---------+---------+ | iter8-seldon/mean-latency | 0.016 | 0.016 | | (milliseconds) | | | +-------------------------------------------+---------+---------+ | iter8-seldon/95th-percentile-tail-latency | 0.025 | 0.045 | | (milliseconds) | | | +-------------------------------------------+---------+---------+ | iter8-seldon/error-rate | 0.000 | 0.000 | +-------------------------------------------+---------+---------+ |
We can check the state of the experiment via kubectl also:
kubectl get experiment NAME TYPE TARGET STAGE COMPLETED ITERATIONS MESSAGE quickstart-exp A/B iris Completed 15 ExperimentCompleted: Experiment Completed |
In the above examples a final stage promotion action is defined for the successful candidate to be updated to the new default Seldon deployment.
You can find a notebook to run this example in the Seldon Core repository.
2. Seldon/Iter8 experiment over separate Seldon Deployments.
We can also run experiments over separate Seldon Deployments. This though would require the creation in your service mesh of choice of a routing rule that Iter8 can modify to push traffic to each Seldon Deployment.
The architecture for this type of experiment is shown below with an Istio Virtual Service handling the traffic configuration over which Iter8 can modify:
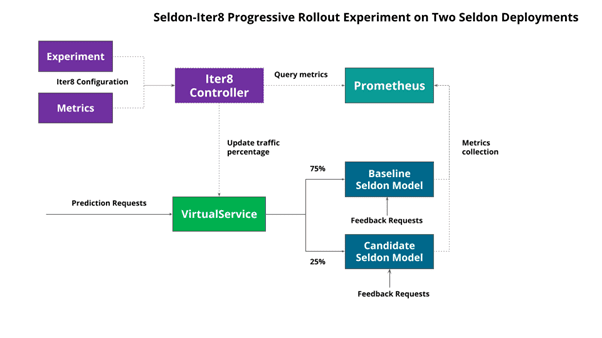
The difference here is we have two Seldon Deployments. A baseline:
apiVersion: v1 kind: Namespace metadata: name: ns-baseline --- apiVersion: machinelearning.seldon.io/v1 kind: SeldonDeployment metadata: name: iris namespace: ns-baseline spec: predictors: - name: default graph: name: classifier modelUri: gs://seldon-models/sklearn/iris implementation: SKLEARN_SERVER |
And a candidate:
apiVersion: v1 kind: Namespace metadata: name: ns-candidate --- apiVersion: machinelearning.seldon.io/v1 kind: SeldonDeployment metadata: name: iris namespace: ns-candidate spec: predictors: - name: default graph: name: classifier modelUri: gs://seldon-models/xgboost/iris implementation: XGBOOST_SERVER |
Then, for Istio we need a new routing-rule to split traffic between the two:
apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: routing-rule namespace: default spec: gateways: - istio-system/seldon-gateway hosts: - iris.example.com http: - route: - destination: host: iris-default.ns-baseline.svc.cluster.local port: number: 8000 headers: response: set: version: iris-v1 weight: 100 - destination: host: iris-default.ns-candidate.svc.cluster.local port: number: 8000 headers: response: set: version: iris-v2 weight: 0 |
The metrics are the same as in the previous section. The experiment is very similar but has a different VersionInfo section to point to the Istio VirtualService to modify to switch traffic:
The progression of the experiment is very similar to the last example with the best performing model being promoted.
You can find a notebook to run this example in the Seldon Core repo.
Summary
By combining Iter8 with Seldon Core you can create well defined experiments to test challenger models against the current running production model and deploy new models to production with confidence.