Performance of machine learning models is key when teams and organisations are looking to deploy models at scale. Achieving optimal performance for a broad range of deployed models involves varying levels of complexity due to the configurations required at the cluster level, deployment level and application level to achieve optimal results. This becomes more complex when handling models from a broad range of heterogeneous machine learning frameworks.
The v1.10.0 release of Seldon Core introduces several improvements and features that address the performance and interoperability capabilities of the serving framework. This version has introduced a range of optimizations that improve the performance of various supported frameworks. Furthermore, we have also introduced a set of best practices that outline how to get the most out of your models, such as tradeoffs between protocols, formats and environment variables, in conjunction with a simple distributed benchmarking suite that allows users to identify the best configurations for their models.
The interoperability improvements in this release include deeper integrations with MLFlow models through our Python v2 MLServer, as well as the upgrading of the alibi detect server for outlier and drift detection to enable for advanced machine learning monitoring.
Performance Improvements and Automated Benchmarking
The models that are deployed using Seldon Core can benefit from a broad range of underlying model servers. These include NVIDIA Triton, TFServing, MLFlow, as well as custom Python, Java and R servers. Each of these servers requires different considerations when introducing performance optimizations, including different environment variables, framework parameters, and complexities even on the model level. This release introduces four key improvements that users will be able to benefit from to enhance the performance of their models.
Automated Benchmarking
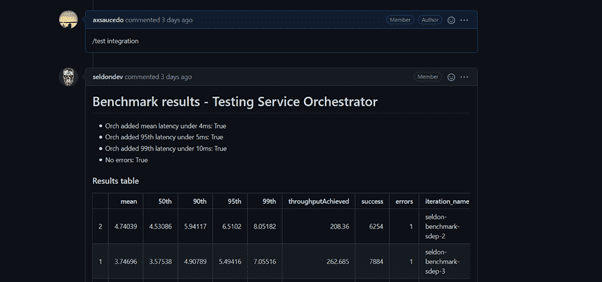
In this release we have added an internal automated benchmarking suite that can now be triggered as part of the continuous integration pipelines that run in our open source repository with Jenkins X. The image below shows an example of the command, and the results from the test, which showcase and compare the performance of specifically the Python servers, but this can be further extended to other highly optimized servers like triton, tfserving, etc. Furthermore we have also made available the manifests that allow Seldon Core users to run their own distributed benchmarking performance evaluation tests which you can find in the documentation.
Performance Optimisation Guides
As part of this release, we have put together a few, and growing number of optimization guides, which aim to provide best practices to seldon core users when looking to introduce performance optimizations to their models. These include information about configuration options, as well as tradeoffs – some of the guides added include:
- Specialised Computation Variables (KMP Affinity)
- Tensorflow Serving Benchmark
- Service Orchestrator Benchmark
- Evaluation of Protocols
Server Parallel Processing
The Python V1 GRPC Server has historically been limited from being able to leverage multi-processing, and unlike REST servers that can benefit from frameworks like Gunicorn, there is no standard solution that addresses this. In this version of Seldon Core, we have introduced performance improvements to enable multi-processing with GRPC by opening multiple concurrent connections from the default service orchestrator. This introduces significant optimizations allowing for CPU-intensive compute to benefit from performance improvements that can increase in orders of magnitude with the number of CPU cores available. This was a fantastic contribution by Seldon Core contributor @mwm5945.
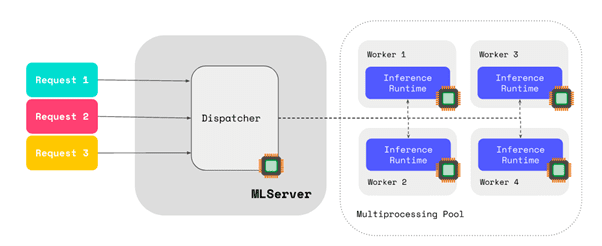
A relevant improvement was also introduced in the Python V2 Server known as MLServer, which enables for parallel inference even for the multi-model serving capabilities. Now MLServer includes support to offload inference workloads to a pool of workers running in separate processes. This allows MLServer to scale out beyond the limitations of the Python interpreter. To learn more about why this can be beneficial, you can check out the more detailed description in the documentation.
MLFlow V2 Server
As part of our current interoperability enhancements to support deeper features of the MLFlow framework, we have added “native” support for MLFlow models in Seldon Core through both the MLFlow serving protocol, as well as the Seldon Core V2 protocol that uses the broader standard adopted by a broad range of model serving frameworks like NVIDIA Triton.
The new MLFlow server has been developed with close collaboration from the MLFlow team, and introduces a broad range of improvements which are outlined in the table below:

We have added an end to end example that allows Seldon Core users to benefit from the new integration of MLFlow, which you can find now in our documentation.
Get Involved
The 1.10.0 release notes provide the full list of changes. We encourage users to get involved with the community and help provide further enhancements to Seldon Core. Join our Slack channel and come along to our community calls.
Want to learn more about Seldon’s technology? Get a demo today