The Kubernetes MLOps ecosystem continues to evolve in maturity, and similarly the Seldon open source projects continue to offer new features to enable for robust deployment, management and monitoring of machine learning models at scale. This release of Seldon Core v1.12.0 introduces maturity in several of its second-generation components, including its new v2 Python Wrapper “MLServer” and v2 Explainer Runtime. This release also includes improvements in the existing servers, as well as better dependency management via the Poetry project. For more details you can view the release changelog.
Python V2 MLServer Graduation 1.0 Release Candidate
We are excited to announce that we are now coming to the GA release of MLServer, our Seldon Core V2 Python Wrapper. This server introduces significant improvements and new features that have been identified from numerous years running the v1 Python wrapper in production. Among those, you can find:
- Multi-model serving, letting users run multiple models within the same process.
- Ability to run inference in parallel for vertical scaling across multiple models through a pool of inference workers.
- Support for adaptive batching, to group inference requests together on the fly.
- Support for the standard V2 Inference Protocol on both the gRPC and REST flavors, which has been standardized and adopted by various model serving frameworks.
To learn more about the full set of features and the different machine learning frameworks supported by MLServer, please check out the MLServer docs. We would love to hear any thoughts, feedback and suggestions from the community!
Advanced Monitoring Component Environment Parity

In this release we introduce a new way in which we define the environment for our Alibi Explain and Alibi Detect servers. We are now using Poetry to fully lock the Python environment – each dependency has their version pinned. This guarantees robust reproducibility and easy means to match the training and runtime environments – compatibility of these two environments guarantees that trained artifacts will run smoothly when deployed in the production.
Steps required to create your own explainers are now clearly documented and we provide detailed e2e example in Jupyter Notebook. More examples on training outlier/drift detectors to follow!
V2 Explainer Runtime
In this release we enabled V2 protocol compliant explainer model deployment to use MLServer Alibi-Explain runtime instead of the legacy pre-packaged explainer server. MLServer Alibi-Explain runtime allows Alibi explain model serving to leverage utilities that MLServer offers such as multi-model serving, adaptive batching, and parallel inference. It also gives users more flexibility in their explainer model environment as different Python versions and custom libraries are now supported (using conda-pack feature in MLServer).
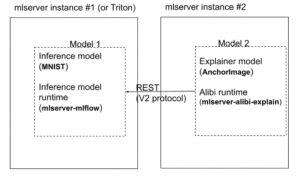
To enable V2 explainer runtime, specify kfserving protocol in Seldon Deployment specification
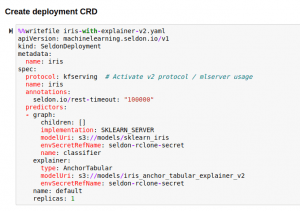
For an end-to-end use case, please check out our notebook example here.
We also added the ability to:
- Create explainers on the fly if users do not require custom Python libraries. In this case no explain model artifact is required for deployment and the system will instantiate an explainer on the fly at deploy time with default parameters. Default parameters can be also changed using explainer.initParameters
- Specify explain call parameters at request time using parameters.explain_parameters. This can be changed for each request, for example to specify a different threshold.
We will be adding more examples in future releases. This feature is currently in incubation stage.
Documentation Structure Refresh
In this version of Seldon Core we have introduced a refreshed structure and major improvement into our documentation. There are now new Installation Guides for specific cloud platforms and for local development installation. This work pathes the way for new quickstart and deployment guides which, with a more model-centric approach, will make getting started much easier (particularly for Data Scientists).
Get Involved
The 1.12.0 release notes provide the full list of changes. We encourage users to get involved with the community and help provide further enhancements to Seldon Core. Join our Slack channel and come along to our community calls.