HuggingFace Runtime, MLServer 1.1 Improvements & Advanced Monitoring Upgrades 🚀
- HuggingFace Optimum Runtime
- V2 Python Wrapper – MLServer 1.1 Feature Improvements
- Request Payload Utilities
- Native Kafka Support
- Updated Architecture for Parallel Inference
- Monitoring Server Upgrades
- Alibi Explain Runtime
- Alibi Detect Runtime
For more a detailed overview on fixes and changes you can view the release changelog.
HuggingFace Optimum Runtime
We were thrilled to announce the release of our new HuggingFace Runtime at KubeCon 2022. This new HuggingFace Runtime provides a simple interface that allows user to benefit from the broad range of pretrained models from the HuggingFace hub, together with optimizations with the ONNX Runtime through the HuggingFace Optimum framework.
This new runtime allows Seldon users to leverage pre-trained models with a simple set of configuration parameters that can be provided directly as part of the model artifact, or through the manifest resource parameters. The base parameters exposed includes “task-type” which supports the “text-generation”, “text-classification”, “question-answering” – between various others. The runtime exposes other parameters such as “optimum” for optimizations, “batch_size” for GPU parallelization, “device” for accelerator selection, among others outlined in the documentation.
You can try this yourself directly with the Python Wrapper MLServer as provided in the documentation example, or by deploying it into Kubernetes directly via Seldon Core in the documentation.

IMAGE LINK: https://mlserver.readthedocs.io/en/latest/examples/huggingface/README.html
V2 Python Wrapper – MLServer 1.1 Feature Improvements
This month we were excited to announce the 1.1 release of our next generation “Python Language Wrapper” which introduces significant improvements on top of the existing multi-model serving features, which are outlined in more detail below.
Request Payload Utilities
Machine Learning models generally expect as inputs higher-level Python data types, like Numpy Arrays or Pandas Dataframes. Since MLServer 1.0, these types of inputs have been modeled in the V2 inference protocol through the use of “content types”. However, the user still needed to know how these payloads should be structured to align with what was expected by MLServer.
To account for this, MLServer 1.1 introduces a new set of utilities to abstract the user from the V2 protocol structure, thus allowing them to fully focus on their inference code.

Native Kafka Support
MLServer 1.1 introduces native support for Kafka, letting you write inference requests directly into Kafka topics, and read their predicted outputs from Kafka. To learn more about this feature, you can check this end-to-end example from the MLServer docs.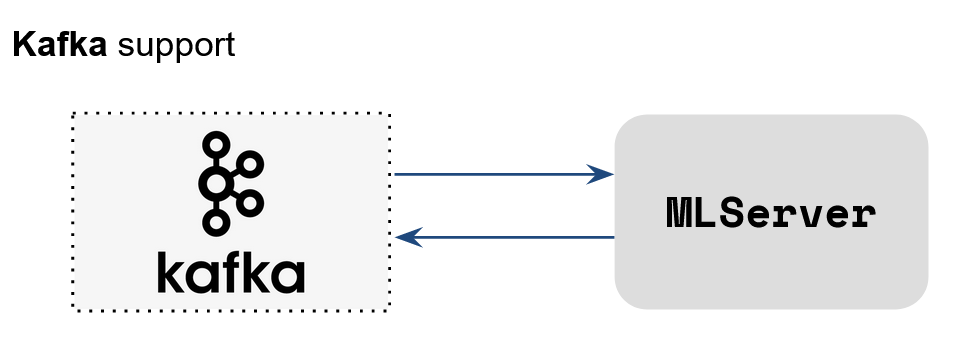
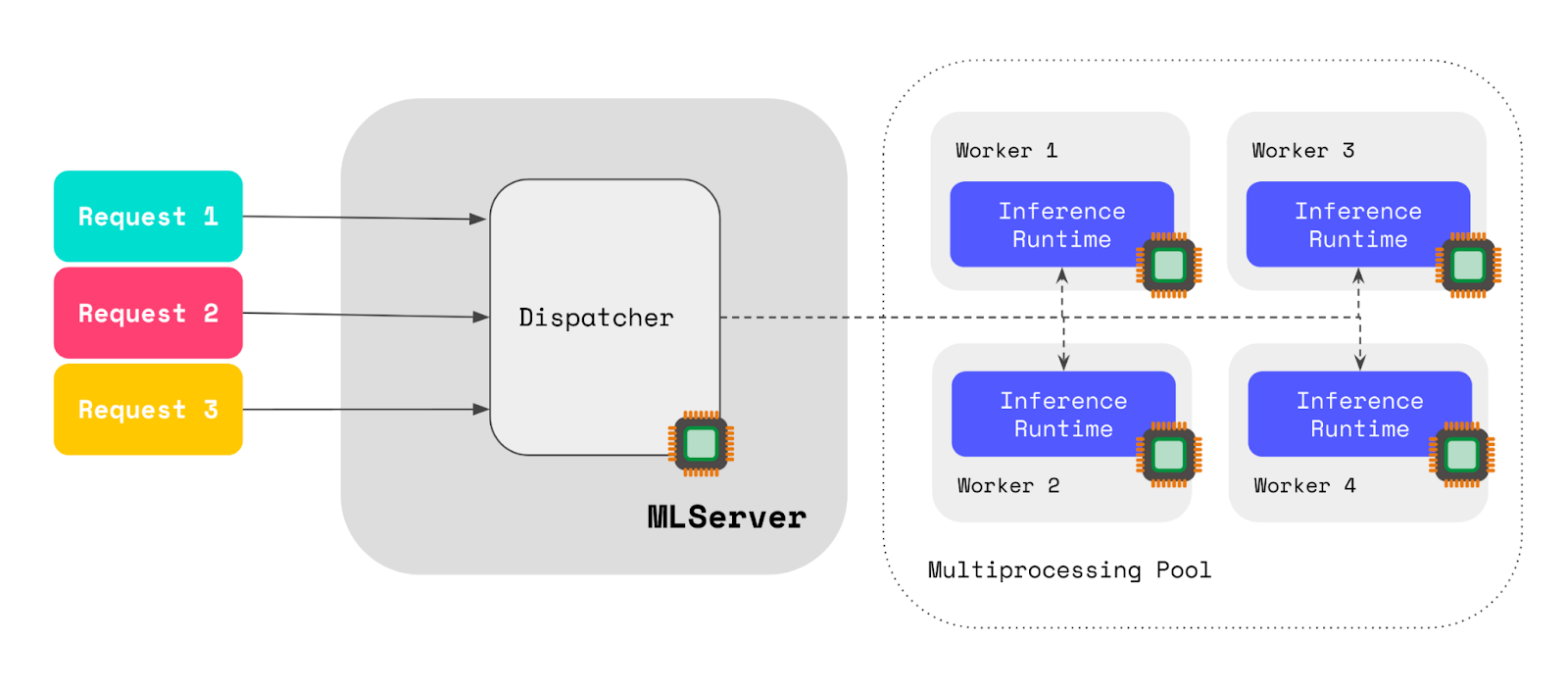
Updated Architecture for Parallel Inference
MLServer 1.1 includes a new revamped architecture for parallel inference, which massively reduces the memory usage overhead added for each model replica. On top of this, this new release of MLServer also includes a number of improvements over the previous load / unload logic.
Monitoring Server Upgrades
As part of this release of Seldon Core we have performed major upgrades on the Alibi Detect & Explain servers, introducing a broad range of new features. This includes the upgrade to Alibi Detect 0.9.0 and Alibi Explain 0.7.0.
Alibi Explain Runtime
Alibi Explain is an advanced machine learning explainability framework that enables practitioners to interpret the inference process of their machine learning models. Seldon has built an Explainer Server that provides a pre-packaged runtime that allows Albi users to deploy their explainer artifacts as fully-fledged microservices that can perform real-time explanations on deployed models. This introduces flexible architectural patterns that enable for interpretation of already deployed models at large scale. The updates in this release introduce minor fixes and improvements to the ALE and IntegratedGradients explainability algorithms as well as two new algorithms, GradientSimilarity and ProtoSelect.
Alibi Detect Runtime
Alibi Detect is a state-of-the-art framework for outlier, adversarial and drift detection, and is used to power advanced monitoring for production machine learning systems at scale. Seldon Core has an integrated Alibi Detect server that provides an optimized runtime for the broad range of detector algorithms provided, allowing for flexible and rich configuration of artifacts created with the Alibi Detect framework. The update in this release adds a new context-aware detector ContextMMDDrift, and fixes around Model uncertainty based drift detection and Text drift detection algorithms.
We also added a new hands on end to end example on creating an Outlier Detector using a Poetry-defined environment which provides a full end to end reproducible environment for data scientists and machine learning engineers looking to productionise advanced monitoring algorithms at scale..
Get Involved
The 1.14.0 release notes provide the full list of changes. We encourage users to get involved with the community and help provide further enhancements to Seldon Core. Join our Slack channel and come along to our community calls.