



At Seldon, we are committed to our open-core strategy and continue to create impactful technology for our open-source community. There are several barriers to not only deploying models and having the ability to do this in a scalable manner. It can be a struggle to build advanced ML applications and advanced data flows, which can prevent a team from using its valuable time and resources in an efficient way. That’s why we are thrilled to announce our latest update of our open-source framework, Seldon Core V2, which is enabling DevOps, ML Engineers, and data scientists to quickly and easily deploy models and experiments at scale. We are proud to have developed Seldon Core V2 in collaboration with [ML@CL] lab from the University of Cambridge.
So, what is Seldon?
Seldon is a data science and machine learning operations organization on a mission to empower MLOps teams to deploy, monitor, explain, and manage their ML models. With Seldon, organizations can minimize risk and drastically cut down time-to-value from their models. We’ve enabled our customers like Exscientia to reduce the time it takes to monitor and prepare models from days to hours.
Our open-source framework is called Seldon Core, which focuses on model deployment, and went through a massive overhaul for its latest update that was announced yesterday during our Core V2 launch webinar event. During the live event, we had several members of the tech and product teams discuss Seldon’s mission and roadmap, and provide an introduction to data flow, an overview of Seldon Core V2, and a demo that showcased all of the exciting new data-centric features. We highly recommend giving it a watch, especially if you’re more of a visual learner.
Now let’s take a look at what you can expect from the new Seldon Core V2 release.
A data-centric approach to model inference with ML-focused Pipelines
Seldon Core V2 follows a software architecture design pattern known as Dataflow. As its name implies, Dataflow is a paradigm that is naturally focused on making data flow (pun intended) through the system. Dataflow focuses on data in all its forms: during input, when it is transformed in ML pipelines, and when it becomes output data. Some Dataflow paradigm examples that data scientists and ML engineers may be familiar with are Tensorflow, Apache Spark, Apache Beam, Metaflow, and Luigi.
Dataflow is easier to understand when it’s compared to Control flow. In contrast to Dataflow, the Control Flow approach focuses on operations, actions, and their order. Object-oriented programming and microservices are good examples of popular control flow approaches.
There are several benefits to using dataflow architecture, which include:
- Complete dataflow graph by design: These graphs can be traversed and manipulated, providing flexibility for fast experimentation.
- Naturally decentralized and asynchronous: Which leads to higher throughput and robustness.
- Data lineage and tracing: This makes it easier to discover, collect, and analyze data at all the different intermediate states.
- Strong data availability: Which helps system owners to assess privacy and compliance of their software.
Multi-model serving with overcommit
Seldon Core V2 addresses the issues that many open-source users had with running each model artifact on a separate server, as they did with Seldon Core V1. Operating with a single model per server paradigm means it’s more challenging to scale to high numbers of models, which likely results in a large amount of wasted infrastructure resources.
Seldon Core V2 empowers users to run multi-model serving. This is achieved by intelligently scheduling models according to server capacity and utilization. Multi-model serving provides a scalable and cost-effective solution when the number of models you are deploying increases.
Both hosting costs and deployment overhead are significantly reduced when utilizing multi-model serving. This is the ideal solution for hosting a large number of models with the same ML framework on a shared serving container.
The two different ways of running models (single-model serving and multi-model serving), and the corresponding improvement in resource utilization, are illustrated below:
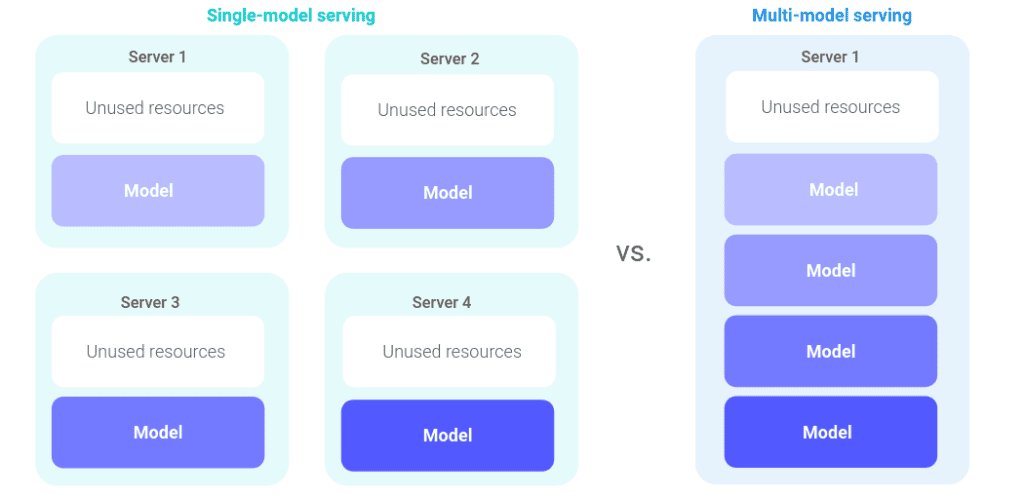
Additionally, Seldon Core V2 takes deployment to the next level by allowing the use of overcommit, where servers can be extended past their physical memory limits. This means a server can handle more models than can fit in memory by keeping highly utilized models in memory, and pushing other ones to disk using a least-recently-used cache mechanism.
New Resource Types: Models, Servers, Pipelines, Experiments
Seldon Core V2 introduces the ability to perform sophisticated operations with a simple new set of deployment system building blocks. We strive to make it as easy as possible to scale to thousands of production machine learning models via advanced ML capabilities that come pre-packaged and out of the box such as:
- Advanced metrics
- Request logging
- Explainers
- Outlier detectors
- A/B tests
- Canaries and more
Other noteworthy new features
- Local Docker and Kubernetes installations
- Data scientists can easily validate and update their models and dependencies in a local production-like environment before deploying the same models into production.
- Simple Unified Kubernetes Integration
- Be empowered to use any service mesh of choice, or the raw Kubernetes service.
- Seldon Core V2 is namespaced and requires no cluster-wide authorization except for the initial creation of the Custom Resource Definitions.
- Broad machine learning artifact support
- Cover a broad range of standard ML artifacts as well as custom python components with our single open inference protocol.

Try out Seldon Core V2 today!
Seldon Core V2 is available now on GitHub, where over 94 million developers shape the future of software together. Our team is excited to continue to contribute to the open-source community, especially when we launch big releases such as this one. Learn more and try it for yourself today:
Looking for enterprise-ready features?
Seldon Deploy Advanced is built on this functionality to power model monitoring, explainability, and management.
As our commercial products are built upon our open-source software, businesses often start their journey with using Seldon Core first then find their way to Seldon Deploy Advanced to unlock enterprise-ready features like pre-built operational and data science dashboards to enable multi persona collaboration.
Request a demo here!