This article was a collaboration between Clive Cox from Seldon and Oleg Avdeev from Outerbounds. Clive is CTO of Seldon and works on various open source projects in the MLOps ecosystem including Seldon Core and Kubeflow. Oleg is co-founder of Outerbounds having formerly worked at Tecton. He is one of the core developers of the open source Metaflow project.
Introduction
As production machine learning systems become more prevalent, there is a growing gap between data scientists who create machine learning models and devops tools and processes to put those models into production. This can lead to training pipelines that are not production ready or difficult to experiment with locally along with resulting models which are not properly validated and isolated from appropriate business logic and associated monitoring for their proper use.
In this article we will show how as a data scientist you can achieve a simple production ready MLOps pipeline using Metaflow and Seldon. Train and deploy your models locally as you build initial versions and then when the time comes to scale out to production with the “flick of a switch” train on AWS and deploy to a Kubernetes cluster running Seldon.
The MLOps Lifecycle
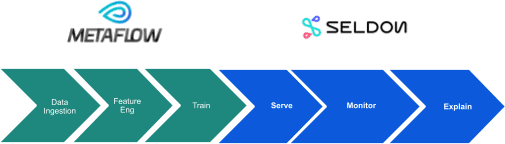
A standard MLOps pipeline can be seen below:

The initial stage involves ingesting the required data to build your model followed by doing the appropriate data engineering to create the required features as input to a training stage where you apply specific machine learning algorithms to create a model artifact that can be used for the desired prediction task. After you have a model artifact you will want to deploy it so predictions can be made from it as well as monitor it for performance, drift and outliers and explain predictions to interested stakeholders.
Metaflow is a project that focuses on the first three steps and Seldon concerns itself with the deployment stages of the last three steps. We will show in this article how they can be easily combined to provide the full ML pipeline.
Local versus Remote Deployment
It’s easier for a data scientist to start developing and testing locally as they build initial versions of their model and try different algorithms. However, at some point they will need to move to remote processing. For the initial stages this can be due to various reasons such as:
- The need to use large data lakes of input data that can be hard to use from a local development environment.
- The need to train the model at scale perhaps with GPUs or with many parallel compute steps to allow for efficient and timely training from large datasets.
Similarly, at some point they will want to deploy their model remotely for various reasons including:
- The need to create a remote and scalable endpoint that can be used in production with no downtime by their end users.
- The need to test their model at scale to ensure correct latency requirements for high throughput demands in production.
The challenge in efficient MLOps is to allow both modes of working: local and remote MLOps with easy transitions as needed between the two while at the same time providing a simple interface to data scientists who may not wish to get involved in the complexities of remote infrastructure setup. Fortunately, Metaflow and Seldon provide elegant solutions for this.
We will start by briefly introducing both projects and then illustrate with an example how they can be combined to provide a powerful end to end solution.
Introducing Metaflow
Metaflow is a human-friendly Python library that helps scientists and engineers build and manage real-life data science projects. Metaflow was originally developed at Netflix to boost the productivity of data scientists who work on a wide variety of projects from classical statistics to state-of-the-art deep learning.
Metaflow provides a unified API to the infrastructure stack that is required to execute data science projects, from prototype to production.
From a technical perspective, Metaflow focuses on making the most “boring” aspects of the data science workflow easy: interacting with the data warehouses, accessing the data, organizing, orchestrating and scheduling jobs, making sure your data pipelines scale in the cloud and a breeze to iterate on using just your laptop. Out of the box, it provides a way to develop the pipeline and track and version the results, ensuring every run is reproducible, by your colleagues or your future self. Metaflow also takes care of “compiling” your data workflows into a production-ready cloud-native AWS or K8S-based infrastructure stack.
Introducing Seldon
Seldon provides a range of products to allow companies to put their machine learning models into production as shown in the image below.

Seldon Core is the flagship open source project that provides an extension to Kubernetes to allow inference for any set of machine learning models to be deployed, scaled and updated. Seldon Tempo is an open source Python SDK that allows data scientists to describe inference components in simple Python, test locally on Docker and deploy to Kubernetes (using Seldon Core) without needing to have any Kubernetes knowledge or interact with YAML and Kubernetes command line tools as would be required in direct Seldon Core usage. Other projects we will not focus on today include Seldon’s Alibi suite of open source Python libraries (Alibi Explain and Alibi Detect) for adding monitoring and explanations to deployed ML models, MLServer an open source Python model server (also used by Tempo under the hood) and Seldon Deploy the enterprise solution from Seldon.
An example Tempo Python model artifact as used later in the worked example is shown below as illustration of the constructs users can create.
sklearn_model = Model(
name="test-iris-sklearn",
platform=ModelFramework.SKLearn,
local_folder=sklearn_local_path,
uri=sklearn_url,
description="An SKLearn Iris classification model",
)
|
Users define simple Model classes directly or via decorators with a set of arguments including the name of the model, the type of artifact (SKLearn model in this case), the local and (eventual) remote locations of the artifacts and an optional description. Given this tempo can deploy locally or remotely your model and allow you to run predictions against it.
Users can also combine components with any custom Python code and library. This allows custom business logic for inference to be defined as shown below:
@pipeline( name="classifier", uri=classifier_url, local_folder=classifier_local_path, models=PipelineModels(sklearn=sklearn_model, xgboost=xgboost_model), description="A pipeline to use either an sklearn or xgboost model for Iris classification", ) def classifier(payload: np.ndarray) -> Tuple[np.ndarray, str]: res1 = classifier.models.sklearn(input=payload) if res1[0] == 1: return res1, SKLearnTag else: return classifier.models.xgboost(input=payload), XGBoostTag |
In the above custom Python logic is defined to call two models. This is created via a Pipeline decorator to the custom Python function that references the two models that will be called along with similar information as for the previous Model components.
Once created, one can deploy, predict and undeploy the components locally or remotely with ease.
Bringing Tempo and Metaflow together
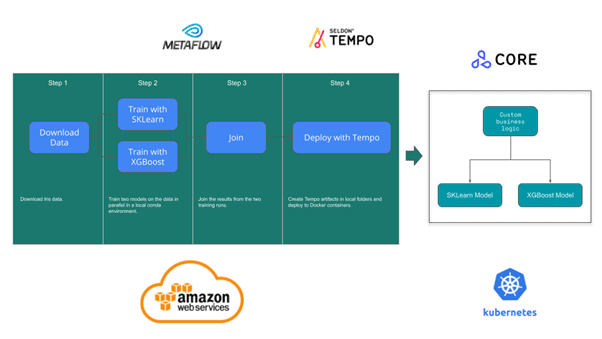
As both Metaflow and Tempo are Python SDKs it’s a simple task to include Tempo as a Step within a Flow. To illustrate we will take the popular Iris dataset and construct two predictive models from it using the SKLearn and XGBoost libraries. We will then define Tempo inference artifacts that call these two models with custom business logic and deploy them. We will use Metaflow to run these steps as shown below.
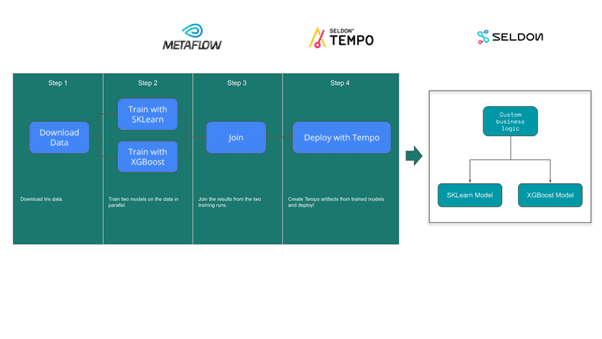
The Flow can be run locally within conda environments. Metaflow will save the artifacts to a local .metaflow folder and Tempo will deploy the artifacts as Docker containers. This local development version is shown below but note for production training you should eventually move to a full Metaflow install on AWS that saves metadata to AWS S3 even if training steps are run locally.
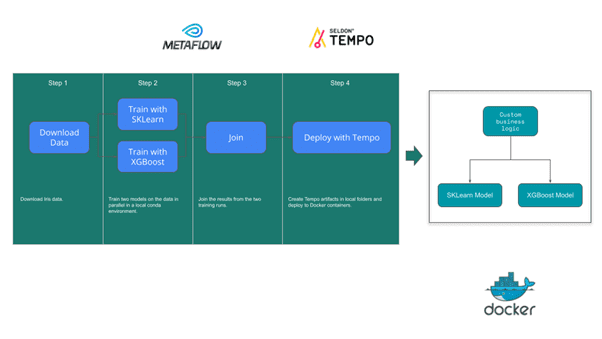
The flow can be run with :
python src/irisflow.py --environment=conda run |
On successful completion you should see three Docker containers running with the Tempo artifacts using the MLServer model server:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c217349601fa seldonio/mlserver:0.4.0 "/bin/bash -c '. ./h..." 13 minutes ago Up 13 minutes 0.0.0.0:32971->9000/tcp, :::32971->9000/tcp classifier 33dc22276740 seldonio/mlserver:0.4.0 "/bin/bash -c '. ./h..." 13 minutes ago Up 13 minutes 0.0.0.0:57305->9000/tcp, :::57305->9000/tcp test-iris-xgboost 4585020f59a2 seldonio/mlserver:0.4.0 "/bin/bash -c '. ./h..." 13 minutes ago Up 13 minutes 0.0.0.0:56311->9000/tcp, :::56311->9000/tcp test-iris-sklearn |
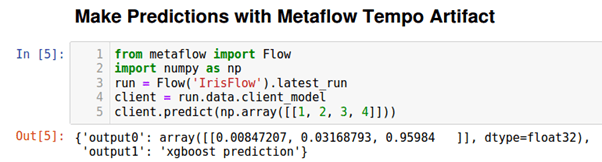
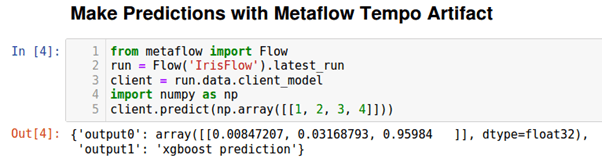
Using the ability in Metaflow to get the artifacts from the latest successful run we can easily make predictions using the saved Tempo remote model artifact.
To run remotely we need to install Metaflow on AWS and have either a GKE or EKS Kubernetes cluster available with Seldon Core installed. Running remotely will allow us to execute on AWS Batch with Metaflow and scale out our training as needed. Similarly, we will be deploying our Tempo artifacts with Seldon Core onto a Kubernetes cluster which will allow production scale out, monitoring and management.
The remote setup is shown below:
The flow can be run with:
python src/irisflow.py --environment=conda --with batch:image=seldonio/seldon-core-s2i-python37-ubi8:1.10.0-dev run |
On successful completion of the run there should be Seldon Deployments running in the Kubernetes cluster.
kubectl get sdep -n production NAME AGE classifier 2m58s test-iris-sklearn 2m58s test-iris-xgboost 2m58s |
As before we can use the Flow Tempo artifact to make predictions as shown below:
A Simple Route to Production ML
By using Metaflow with Tempo a data scientist has a powerful combination to develop end to end machine learning pipelines with switching between local and remote development as needed. Both projects also provide auditing and reproducibility. Metaflow stores all artifacts created at each step to allow easy rerunning of any Flow. Tempo in combination with Seldon Core provides yaml outputs which can be used as an alternative to deploy artifacts via the GitOps paradigm to allow clear updates and rollback as needed when new versions of the pipeline are run and deployed.
For further details a fully worked example is provided in the Tempo repository and docs.
If you have any questions or want to learn more feel free to join our Slack communities:
Want to find out more about Seldon? Get a demo today.