Organisations have a growing need to adopt architectural patterns that allow them to deploy, promote and monitor their models at scale. This encompasses advanced configurations that are necessary to be able to run rich A/B tests at scale with minimal manual intervention.
The Seldon Core 1.9 release aims to tackle this with several new features and functionality. The core highlights of this release include integration into IBM Research’s Iter8 project which enables for advanced and configurable progressive rollouts enabling machine learning practitioners to set up A/B and automated evaluation tests across deployed models. In this release we also freshened up our Documentation, added further fixes for the Tempo SDK integration, introduced V2 Protocol Support for the Alibi Explain Server, and various other improvements which you can find in the changelog.
Iter8 Integration for Progressive Rollouts
Iter8 is an open source project that makes it easy to optimize business metrics and validate SLOs when deploying K8s apps/ML models through declarative cloud native progressive rollouts. We have integrated Seldon Core with iter8 to enable advanced use cases on experimentation utilizing clear objectives and rewards for candidate model selection. Iter8 also provides progressive rollout capabilities to automatically allow testing of candidate models and promoting them to the production model if they perform better than the current production model.
In this release of Seldon Core we have added two examples:
1. Seldon/Iter8 Experiment over a single Seldon Deployment.
The first option is to create an AB Test for the candidate model with an updated Seldon Deployment and run an Iter8 experiment to progressively rollout the candidate based on a set of metrics. The architecture is shown below:
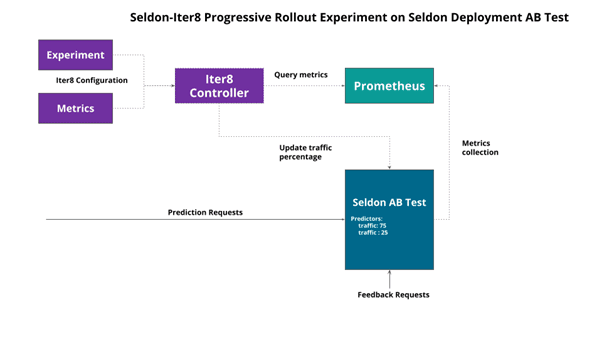
2. Seldon/Iter8 experiment over separate Seldon Deployments.
We can also run experiments over separate Seldon Deployments. This though would require the creation in your service mesh of choice for a routing rule that Iter8 can modify to push traffic to each Seldon Deployment.
The architecture for this type of experiment is shown below with an Istio Virtual Service handling the traffic configuration over which Iter8 can modify:
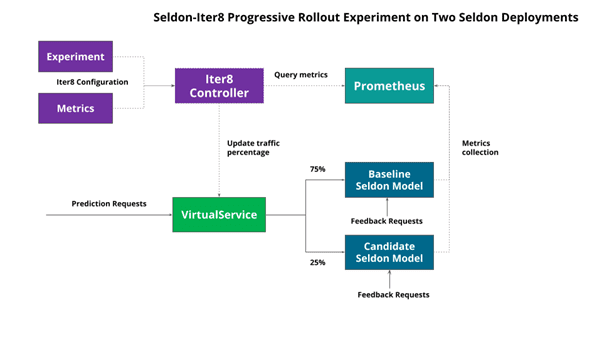
A more detailed description of these integrations can be found in our documentation.
Documentation Refreshed Look
In this release we have also updated the styling of our documentation to have a more modern and intuitive interface, leveraging the Material for MkDocs styling providing a smoother experience. Any feedback on the new documentation is always greatly appreciated as always.

Alibi Explain V2 Server Support
Part of our contributions to machine learning deployment and serving have also gone into the workstreams that have worked on the standardisation of the protocol used for model servers, which we refer to as the V2 protocol. The V2 protocol has now been adopted by various projects besides Seldon Core, including KFServing, and NVIDIA Triton. In this release we have extended the support for the V2 protocol to our machine learning explanations server which uses the Alibi explain library.
Miscellaneous Fixes
- Replicas set on explainers are now correctly handled. This allows users to scale the replicas for the explainer separately from the core deployment. This also fixes the case where replicas are set to zero in which case the explainers are also scaled to zero.
- Users can now provide an annotation for the Istio Host to use when Seldon Core creates VirtualServices automatically for your deployment. Using the seldon.io/istio-host annotation users can limit their exposed services to those matching the host provided.