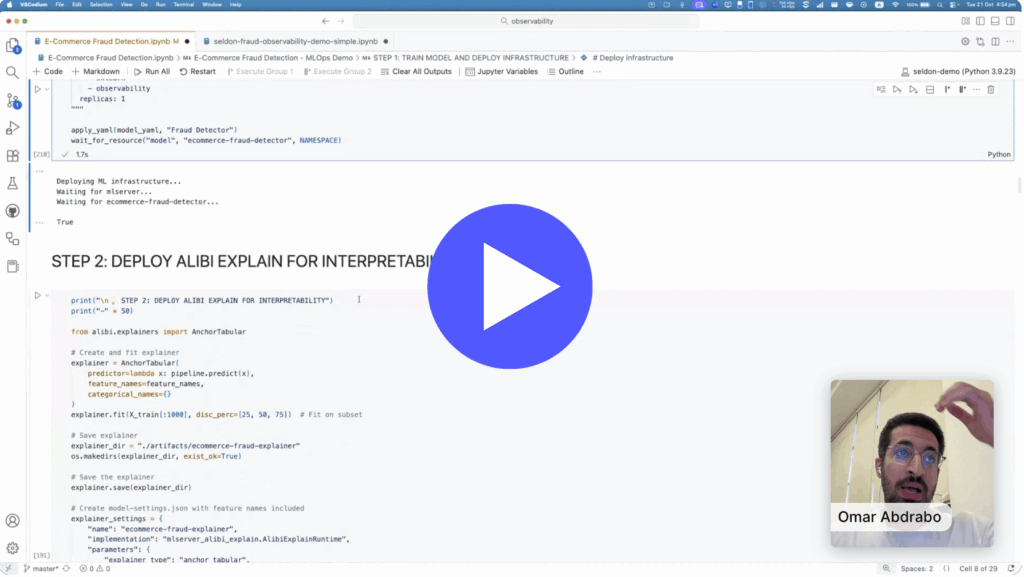
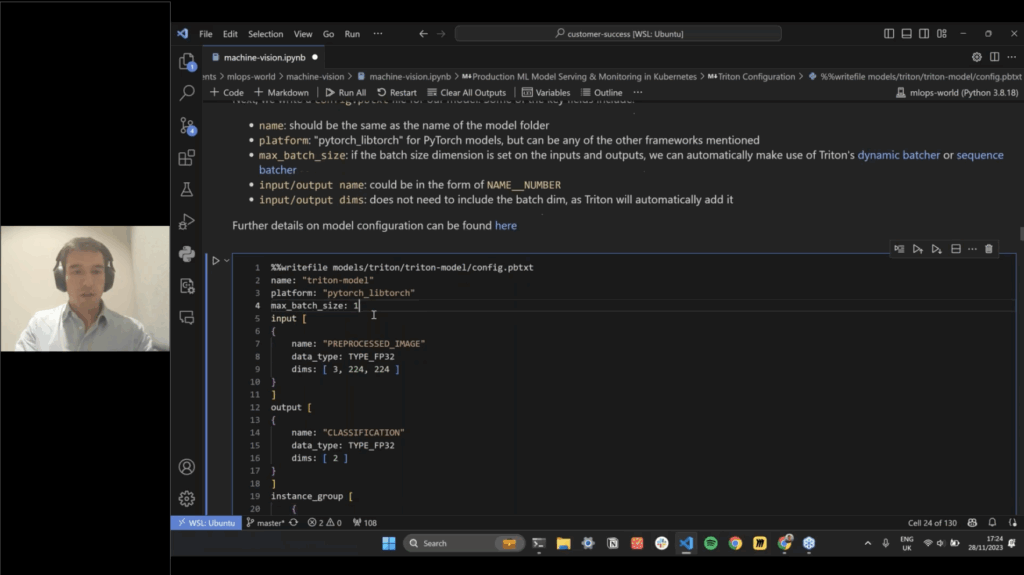
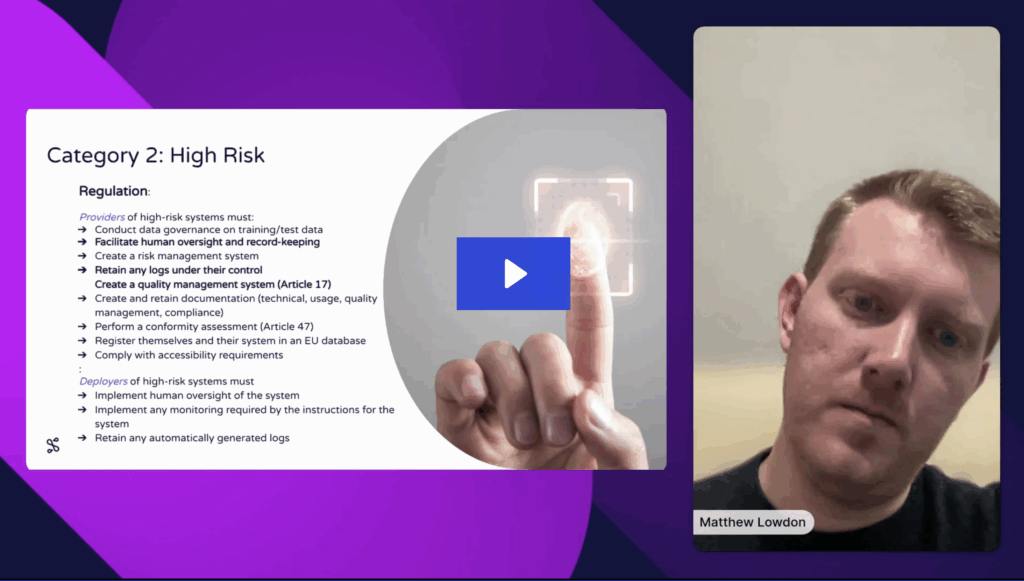
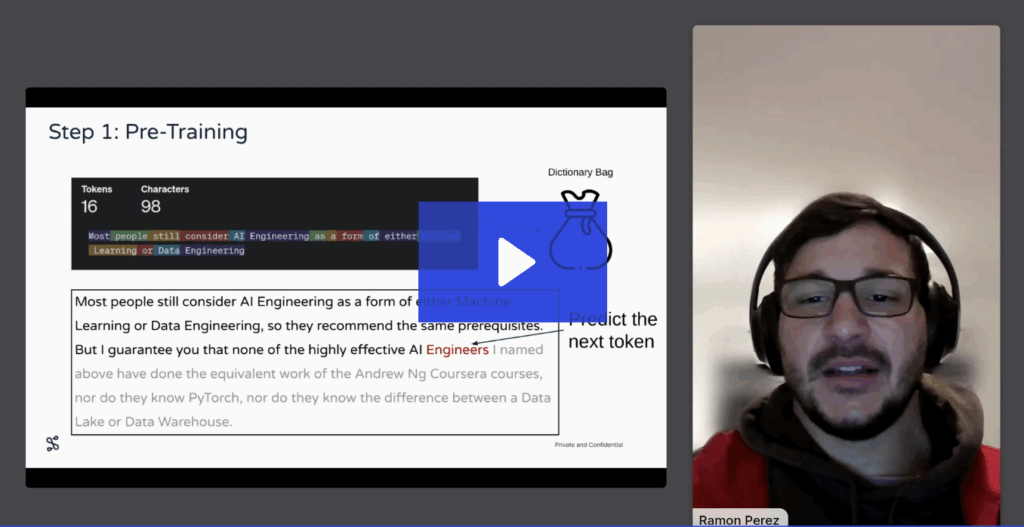
Learn how to build a production-ready ML pipeline that combines large language models (LLMs) with traditional ML using Seldon Core 2. In this demo-led session, the Seldon team shows how to seamlessly integrate an LLM from Hugging Face with a classic scikit-learn model inside a modular, observable, and fully traceable pipeline all running on Kubernetes.
Whether you’re aiming to improve unstructured data handling or simplify complex workflows, this demo offers a real-world example of LLM orchestration that’s scalable, explainable, and production-ready.