
How to deploy, monitor, explain, and continuously improve traditional machine learning use cases in production with confidence.
The Hidden Challenge of traditional ML in Production
A fraud detection model is trained and performs well during development, giving stakeholders confidence in its potential. But once the model is deployed to production, the situation changes. Within weeks, legitimate transactions begin to be flagged unexpectedly, customer complaints rise, and the data science team is left scrambling to understand what went wrong.
This scenario highlights a common challenge in machine learning: bridging the gap in monitoring needs between model development and production deployment. Strong performance in a controlled environment does not guarantee reliability in the real world. To operate successfully in production, it is essential to understand why a model makes certain decisions, recognise when its performance is degrading, and monitor how production data differs from the data it was trained on.
The Four Pillars of ML Observability
Many machine learning projects run into trouble not because their model is poorly designed, but because teams lack visibility into how it behaves once deployed. Models that perform well in development often degrade in production due to unexpected edge cases, silent failures, or distribution changes that can’t be accounted for when training the model.
Without implementing a strong observability suite, these issues can go unnoticed until they create customer impact, erode trust, or force expensive emergency interventions.
Stakeholders often underestimate this risk. Under pressure to ship features, meet deadlines, or demonstrate AI progress, monitoring is treated as optional rather than essential. But industry surveys consistently show that model degradation, undetected drift, and unreliable predictions are among the top reasons ML systems fail in production. In other words: observability is not a luxury, it is the foundation of long-term model reliability and business value.
To address these challenges, organizations need a structured approach to understanding and monitoring their models in real time. The following four pillars of ML observability provide that foundation, helping teams keep models transparent, adaptive, and aligned with real-world conditions.
1. Performance Monitoring: Tracking What Matters
A model’s performance in development is only a baseline. In production, teams need real-time visibility into precision, recall, false-positive rates, and the metrics that tie model behaviour directly to business outcomes. Alongside these metrics, operational metrics like latency, throughput and resource utilization are important for teams to ensure their systems are running smoothly and as intended.
Performance monitoring helps teams detect issues early, and prioritize fixes based on real customer and financial impact. Without this feedback, issues accumulate silently until they reach emergency levels.
2. Model Interpretability: Understanding the “Why”
Every prediction should be explainable. When a fraud model flags a transaction, teams need to understand which features influenced the decision, not only for debugging, but also for building trust with business stakeholders and addressing growing regulatory expectations around AI transparency. Interpretability provides the foundation for responsible ML by ensuring that decisions can be audited, understood, and challenged when needed.
3. Drift Detection: Catching Changes Early
The conditions a model was trained on rarely match the conditions it operates in. Customer behaviour shifts, new fraud tactics emerge, data pipelines evolve, and external events reshape patterns overnight.
Drift detection identifies these changes before they lead to customer-visible failures or financial impact. When organizations lack drift monitoring, degradation often goes unnoticed until it has already caused significant downstream damage, a key reason 67% of AI initiatives fail to deliver expected value, according to McKinsey.
4. Safe Retraining & Deployment: Closing the Loop
Monitoring alone does not improve models, it only reveals where they are degrading. The final pillar is the ability to act on those insights through safe, governed retraining and redeployment.
This includes capturing ground-truth labels, triggering retraining workflows, running controlled experiments, and rolling out updated models without introducing downtime or new risks. When done well, this closes the loop between monitoring and iteration, enabling teams to continuously adapt their models as the real world changes.
Use Case: Adding Observability to an E-Commerce Fraud Detection System
Let’s implement these concepts with a real-world example: an e-commerce platform running a fraud detection model, supported by the Seldon suite of products to ensure transparency, reliability, and continuous monitoring.
- Core 2: Enables deployment of a real-time fraud detection application with a modular, data-centric framework that scales seamlessly during peak transaction volumes.
- Alibi Explain: Provides clear explanations for fraud predictions, helping teams meet compliance requirements and build trust in automated decisions.
- Alibi Detect: Monitors for outliers and drift in transaction data, ensuring fraud detection models adapt to evolving fraud tactics.
- Model Performance Metrics (MPM): Delivers full observability of fraud detection pipelines with metrics on accuracy, drift, and efficiency in unified dashboards.
System Architecture The Challenge
The e-commerce platform needs to:
- Detect fraudulent transactions in real-time
- Explain why transactions are flagged
- Monitor for new fraud patterns
- Track model performance with actual fraud outcomes
Understanding the Data
The fraud detection model uses five key features that show distinct patterns between legitimate and fraudulent transactions:
Order amount: Fraudulent transactions tend to cluster at much higher values
Account age: Fraud often originates from newly created accounts
Shipping distance ratio: Fraudulent purchases are more likely to involve unusual delivery distances
📊 Feature Distributions:
📊 Feature Distributions:
Order Amount ($)
Normal: ▁▂▄█▆▃▂▁░░░░░░░ Peak: $200-300
Fraud: ░░░░░░░▁▂▃▆█▅▂▁ Peak: $1500-2000
Account Age (days)
Normal: ▁▂▃▅█▇▅▃▂▁░░░░░ Peak: 180 days
Fraud: ▅▇█▆▃▁░░░░░░░░░░░ Peak: <5 days
Shipping Distance Ratio
Normal: █▇▅▃▂▁░░░░░░░░░ Peak: 0.1-0.2
Fraud: ░░░░░░░░▁▃▅▇█▆▃ Peak: 0.8-0.9Step 1: Deploy with Built-in Observability
With Seldon, deploying a model with observability capabilities is straightforward:
apiVersion: mlops.seldon.io/v1alpha1
kind: Model
metadata:
name: ecommerce-fraud-detector
spec:
storageUri: "gs://your-bucket/fraud-detector/"
requirements:
- sklearn
- observabilityOnce the model is deployed, Seldon will set up metrics collection, request tracking, and performance monitoring out of the box. No code changes required.
Step 2: Add Explainability with Seldon Alibi Explain
Understanding why a model makes specific predictions and why a transaction was flagged is crucial for fraud detection:
apiVersion: mlops.seldon.io/v1alpha1
kind: Model
metadata:
name: ecommerce-fraud-explainer
spec:
storageUri: "gs://your-bucket/fraud-explainer/"
explainer:
type: anchor_tabular
modelRef: ecommerce-fraud-detectorWhen a transaction is flagged, the system generates clear explanations:
- “Transaction flagged because: order_amount > $2000 AND account_age < 5 days”
- “Precision: 64% – When these conditions are met, 64% are fraudulent”
- “Coverage: 40% – These rules apply to this subset of fraud cases”
This transparency enables:
- Customer service teams to explain decisions to customers
- Compliance teams to document decision processes
- Data scientists to debug model behavior
Step 3: Implement Drift Detection with Seldon Alibi Detect
Fraud patterns evolve constantly. Alibi Detect monitors for these changes:
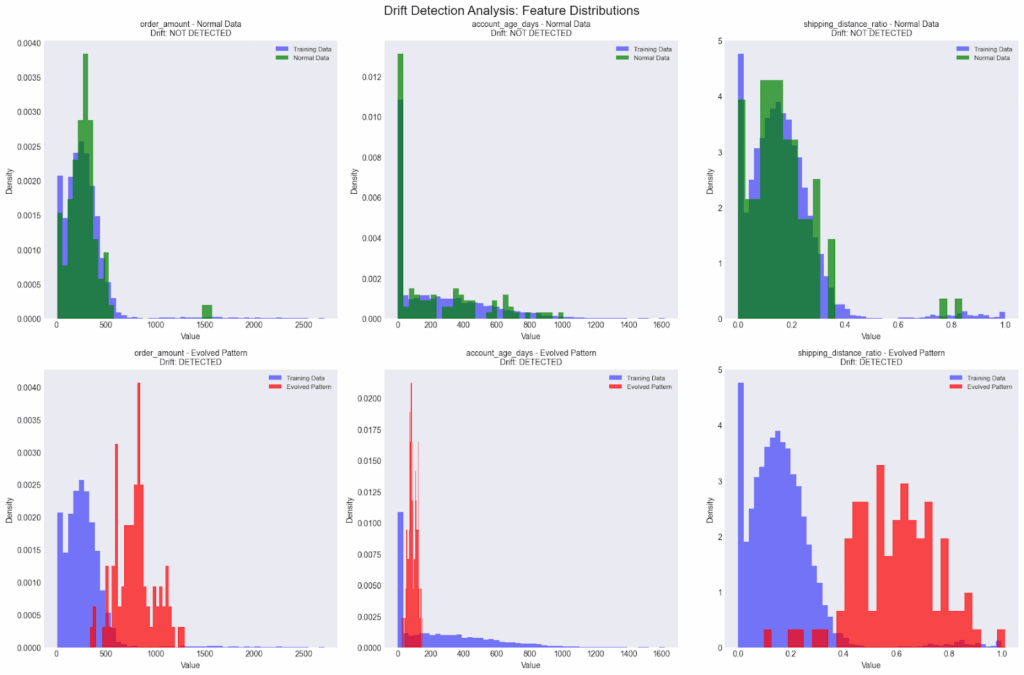
The charts above compare feature distributions from training data against two production scenarios:
(1) normal traffic, where distributions remain stable (no drift detected), and
(2) an evolved fraud pattern, where distributions shift significantly (drift detected).
The system successfully:
- Shows no drift for normal data patterns (green distributions)
- Detects drift in evolved fraud patterns (red distributions)
- Alerts when data distributions shift significantly
This early warning system allows teams to adapt before performance degrades.
Step 4: Create the Monitoring Pipeline
Seldon Core 2 Pipelines combine the drift detector into a single unit, allowing models and detectors to be composed into a single monitored workflow:
apiVersion: mlops.seldon.io/v1alpha1
kind: Pipeline
metadata:
name: ecommerce-fraud-monitoring
spec:
steps:
- name: ecommerce-fraud-detector
- name: ecommerce-drift-detector
batch:
size: 50 # Batch for drift detection
output:
steps:
- ecommerce-fraud-detectorUse the pipeline endpoint for predictions to enable full monitoring:
python
"http://seldon/v2/models/ecommerce-fraud-monitoring.pipeline/infer"Step 5: Performance Monitoring with Feedback using Seldon’s (Model Performance Metrics)
Monitoring predictions alone is not enough to understand how a model performs in the real world. To measure true business impact, models need to be evaluated against actual outcomes once they become available.
Seldon’s Model Performance Metrics (MPM) module enables this by allowing teams to send ground-truth feedback back into the system. This feedback is then used to compute real production metrics such as accuracy, precision, recall, and false-positive rates over time.
This enables accurate, time-based production metrics such as precision, recall, false-positive rate, and accuracy, all computed from real outcomes rather than offline test data.
The following example shows how to configure an MPM subscription for a fraud classification model and how to send ground-truth labels once a transaction outcome is known.
Implementing Feedback Loops
python
# Configure MPM subscription for classification, Register a fraud classification model with MPM so it knows how to interpret prediction outputs
subscription = {
"modelName": "ecommerce-fraud-detector",
"pipelineName": "ecommerce-fraud-monitoring",
"featuresMetadata": [{
"categorical": {
"categories": ["legitimate", "fraudulent"],
"name": "fraud_class"
}
}]
}
# Send ground-truth feedback once the actual transaction outcome is known.
feedback = {
"requestId": request_id, # From response headers
"feedback": {
"classificationFeedback": {
"value": actual_fraud_label # 0 or 1
}
}
}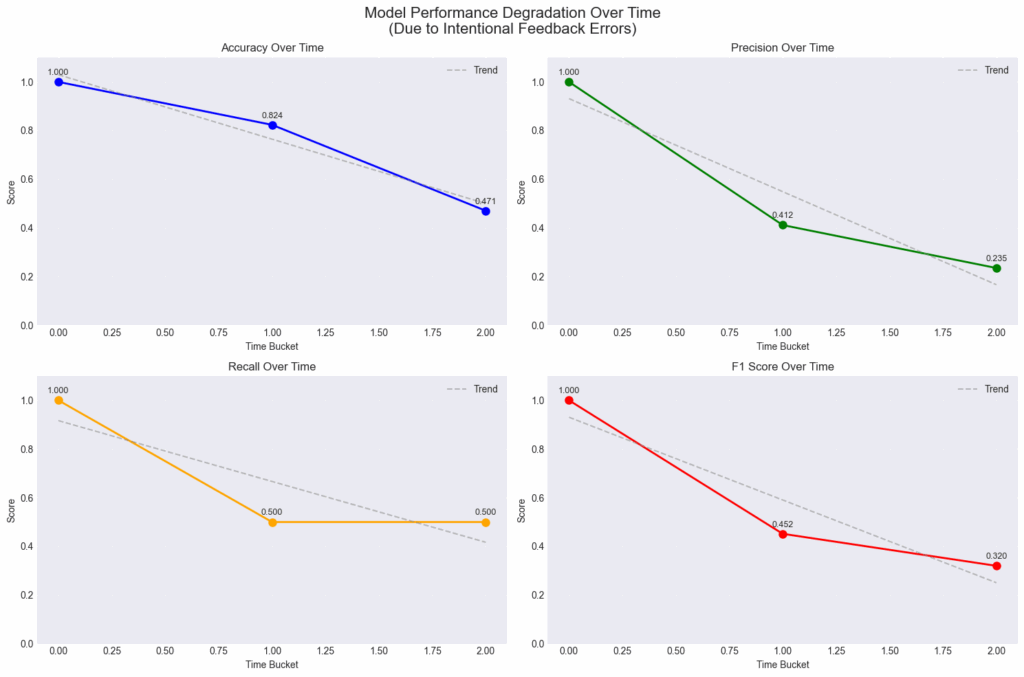
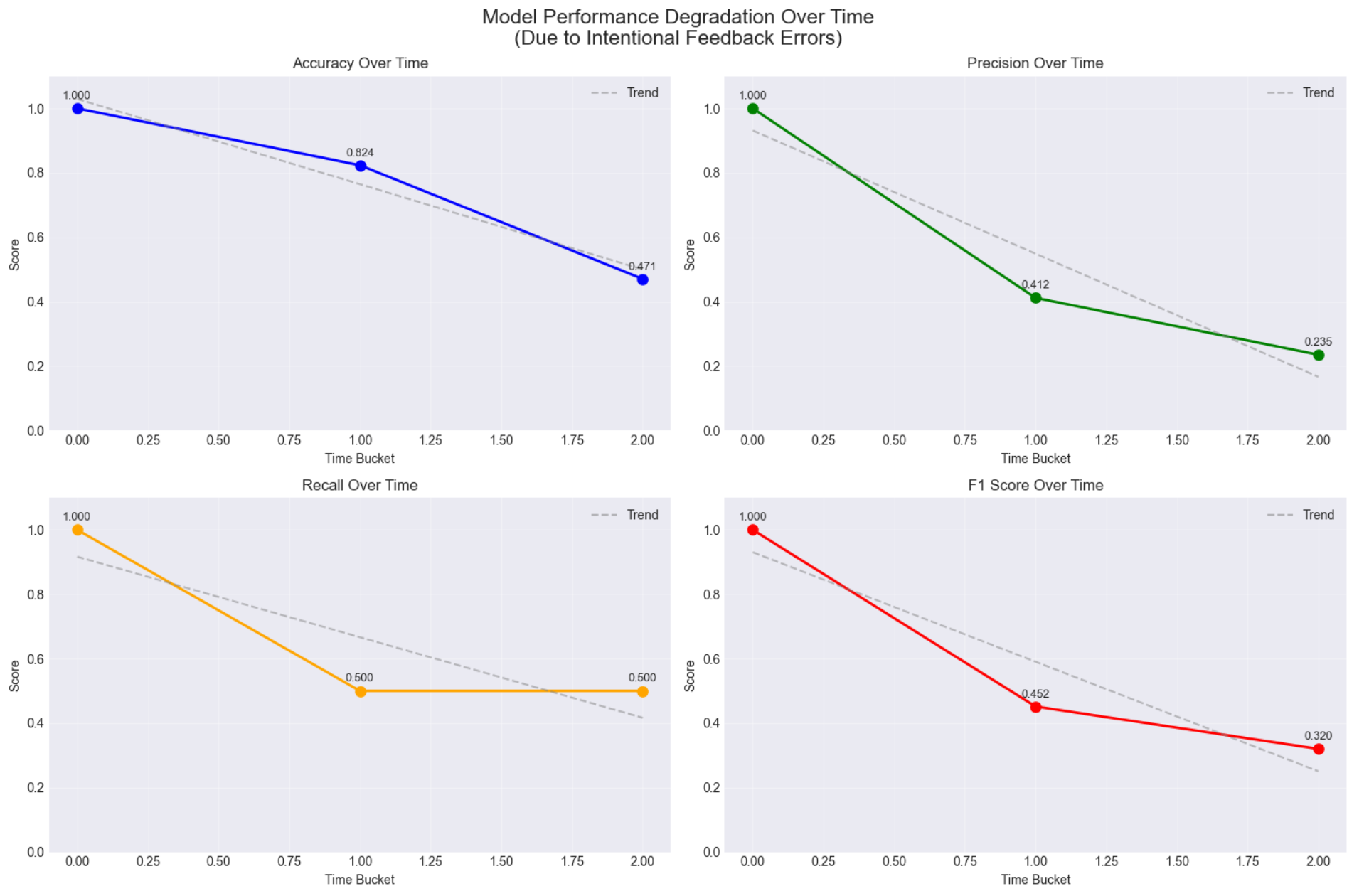
The monitoring system reveals performance changes over time. In this demonstration:
- Initial performance: 100% accuracy
- Gradual degradation detected as feedback quality changes
- Final performance: 47% accuracy
This demonstrates how Seldon’s Model Performance Metrics (MPM) Module catches model degradation that would otherwise go unnoticed until business impact becomes severe.
Key Observations
Time-Bucketed Metrics: The system automatically aggregates performance into configurable time windows, making trends visible.
Drift Detection Works: Normal data passes without alerts while evolved patterns trigger immediate detection.
Explainability Provides Value: Explanations help resolve customer issues and build trust.
Best Practices
Start Simple: Deploy basic monitoring first, then add explainability and drift detection.
Automate Feedback: Manual feedback is unsustainable. Integrate with business systems to capture ground truth automatically.
Monitor What Matters: Focus on business-relevant metrics, not just model accuracy.
Why Observability Matters for Your Business
ML observability isn’t just a technical safeguard, it’s what keeps models delivering real business value over time. Without it, organizations risk model degradation: a slow, often invisible decline in performance caused by drift, changing user behavior, and evolving real-world conditions, leading to mounting costs, missed opportunities, and a steady erosion of trust.
As degradation accumulates, rare signals disappear, accuracy declines, and over time models drift further from reality, meaning the risk isn’t just technical – it’s strategic.
As ML and AI create new opportunities for innovation, stakeholders have to also invest in observability tactics like explainability, drift detection, and feedback loops to ensure innovation can continue beyond maintenance. Leveraging data-first frameworks like Seldon, organizations can make sure that:
- Every decision is explainable: Stakeholders and regulators can see the “why” behind outputs.
- Issues are resolved faster: Teams respond confidently when questions arise.
- Drift is caught early: Shifts in customer behavior or fraud patterns are flagged before they escalate.
- Models keep improving: Feedback loops turn every prediction into a chance to learn.
- Stakeholder trust grows: Transparency transforms ML from a black box into a business asset.
The fraud detection example shows this in action: observability turns fragile experiments into systems that can be trusted, scaled, and measured against real outcomes. In other words, ML observability is the difference between a model that quietly degrades and one that drives lasting growth.
Many ML projects fail to reach production, or fail shortly after, not because the models are poor, but because teams lack the observability needed to operate them with confidence.
With proper observability, that gap becomes a bridge: one that carries models safely into production, where they can be monitored, explained, improved, and tied directly to real business outcomes.
Seldon helps teams build that bridge.
Next Steps
- Explore the complete notebook implementation
- Read Seldon Core 2 documentation
- Learn about Alibi Explain and Alibi Detect
- Schedule a demo to see the platform in action
The code examples in this post are from a working demonstration available in the Seldon solutions repository.




