
In the last three years adoption of AI across industries has increased by 56% [1]. This growth has translated into a surge of AI use-cases reaching production, where in the last two years, the number of use-cases deployed per company more than doubled [2]. This growth has exposed new challenges for companies that are deploying and scaling more AI than ever, notably how to control and reduce total cost of ownership when operating many AI use-cases in production at scale.
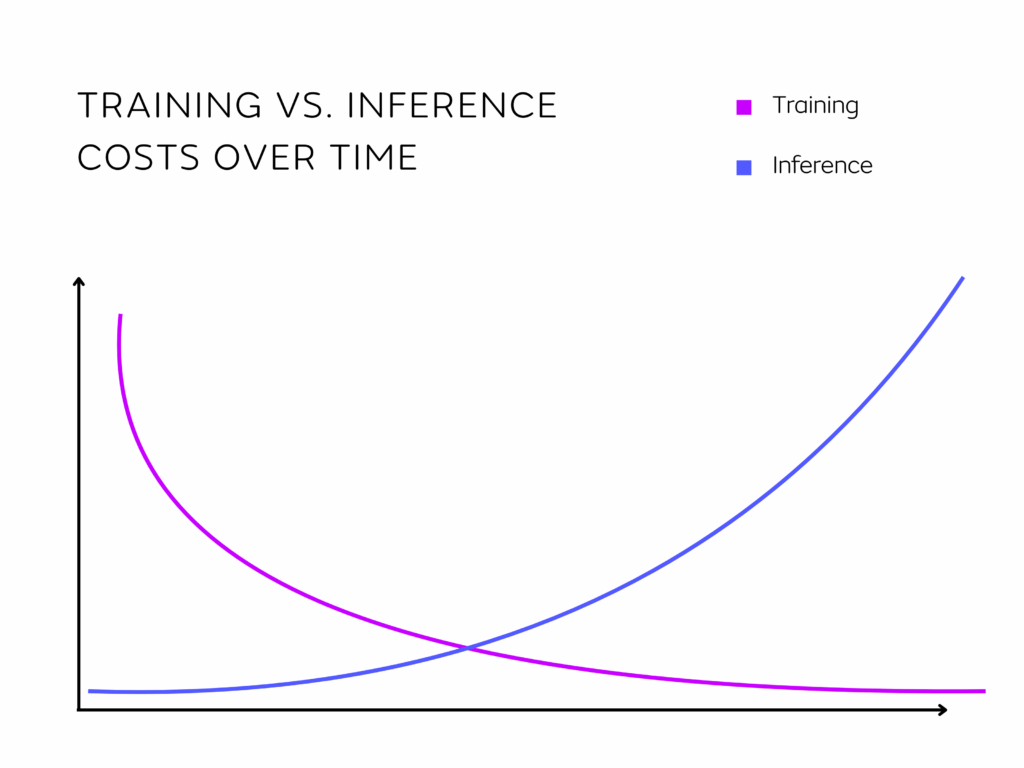
The cost of developing, deploying, and scaling AI applications can be broken down based on the different stages of the ML lifecycle, from ideation and training to building, deployment, and scaling. Generally, for AI applications that will receive high levels of traffic (>100s of requests per second on average), ongoing costs of inference outweigh training costs over time. This is because training is often executed discretely with the aim of producing increasingly performant models, whereas inference costs are incurred on an ongoing basis and scale based on usage over time. Several sources, including Amazon and NVIDIA, estimate that “inference accounts for up to 90% of the machine learning costs for high-scale deployed AI systems” [3].
Operationalizing AI results in direct costs from compute and data storage infrastructure, as well as indirectly by way of the engineering effort needed to build on and maintain production systems. Additionally, creating a comprehensive MLOps framework supports financial goals indirectly by facilitating the development of applications with a wide variety of business use-cases. In other words, a considered approach to MLOps can help maximize the business value captured by AI by providing an efficient process by which to iterate on AI applications and maintain uptime, for example.
Let’s explore how to reduce direct costs in the deployment, scaling, and management (in production) part of the ML lifecycle. We will explore the key cost drivers and share practical optimizations that can help teams run and maintain AI applications and inference at scale in production systems as efficiently as possible.
Cost Drivers in AI Deployment and Inference
Defining Requirements
Once a Data Scientist or ML engineer has created a model that performs well for its intended use-case, the process of integrating that model into a production-ready system can start. At this point, various aspects of production deployment and their trade-offs should be considered:
- Latency and Throughput: how quickly do responses need to be returned?
- Traffic: how many requests will the system need to handle over time?
- Cost limitations: what is an acceptable cost profile for operating AI use-cases?
These aspects will have trade-offs against each other. For example, use-cases that require especially low latency might necessitate more expensive compute infrastructure, like GPUs (or even TPUs) as opposed to only CPUs. GPUs and CPUs can also vary in their own performance profiles and cost across machine types.
It is best practice to first define the most important requirements of a given business use-case (e.g., latency, throughput, etc.), and then optimize the implementation of that use-case such that those requirements are still met. For example, latency and throughput needs can be assessed first, as well as the magnitude of traffic the system will experience, before designing the implementation.
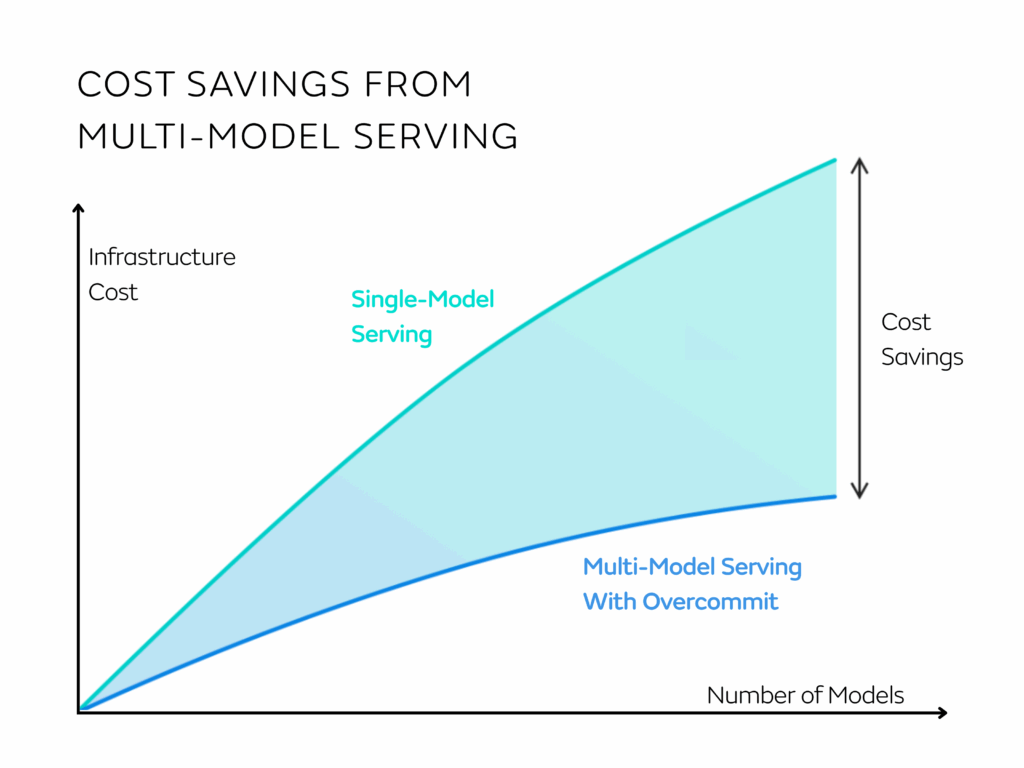
In cases where many applications are to be put into production, it is important to also consider that applications can be hosted on shared infrastructure in order to consolidate costs as much as possible across use-cases. This is something Seldon Core 2 offers in the form of Multi-Model serving, where multiple models use shared inference servers and underlying infrastructure.
Reducing Cost in Operationalizing AI
Models
When it comes to reducing the cost of deploying and running AI in production, efficient model serving can be prepared before even considering production infrastructure. Model-level cost optimization focuses on making models smaller, faster, and more efficient without sacrificing the output quality needed for a given business use-case.The following techniques can reduce the memory and compute footprint of individual models:
- Quantization cuts compute and memory needs by lowering number precision for model weights and activations (e.g., from float32 to int8 or fp16)
- Pruning reduces model size and speeds up execution without impacting performance by removing low-impact weights or neurons
- Knowledge Distillation trains smaller models to replicate a larger models’ behavior, keeping most of the performance at a fraction of the cost.
If multiple model implementations are considered, dynamic model routing lets systems direct requests to different models, only using larger, more complex implementations when required.
By leveraging any of the optimizations above, latency and throughput requirements can be met with less expensive hardware, and cost can be saved by reducing or releasing provisioned hardware based on the needs of the underlying models.
Inference
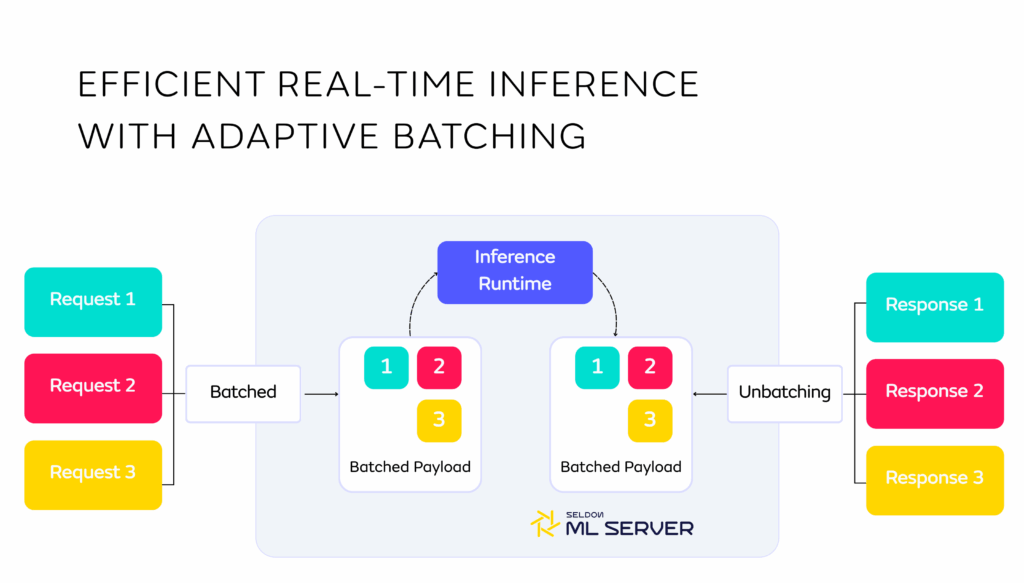
Once a model artifact is ready, the way in which inference is executed is another area where efficiency improvements can be explored. There are several options there that can reduce costs while maintaining performance. For example, if there is some latency leeway, dynamic or adaptive batching can help capture some of the efficiency benefits of batch processing while still meeting real-time or near-real-time latency. Using this technique, the inference serving system collects incoming requests for a short, configurable time window (often just a few milliseconds) and batches as many as possible before sending them to the model. Many serving frameworks like Seldon’s MLServer or Triton Inference Server offer dynamic or adaptive batching.
There are many other inference techniques to consider:
- Caching results avoids unnecessary re-computation when a use-cases’ outputs repeat or change infrequently. This can be a powerful win for recommendation systems, search, or other settings that experience recurring queries.
- Parallel execution with multiple workers or processing streams ensures that GPUs and CPUs are kept busy, improving throughput and lowering cost per inference by reducing idle time.
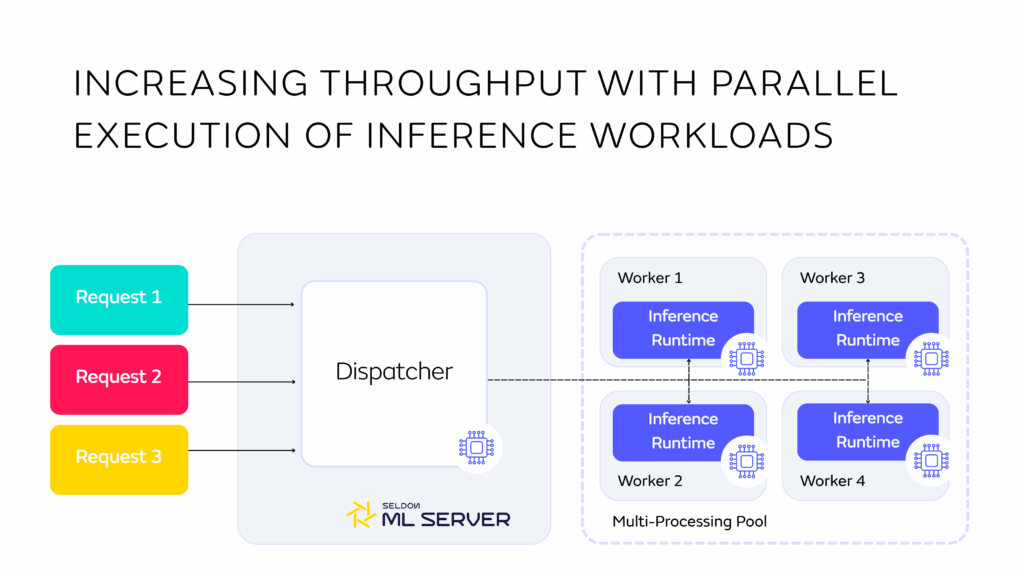
- Finally, optimized runtimes like ONNX or TensorRT can compile and fine-tune models for specific hardware, cutting execution time and resource use.
Combined, these techniques described in this section can make it possible to serve AI at scale without burning through budget.
Choosing Hardware for Production Inference
Once there is a view of business needs in terms of latency, throughput, and cost limitations, as well as how that inference will be executed, developers can start assessing what hardware setups will meet those requirements. The key is to right-size hardware to actual needs and avoid the ‘bigger is better’ trap. To do this, benchmarking your models on multiple hardware SKUs (e.g. T4 vs A10 vs A100, or Inf1 vs general CPU) can help identify the best performance-to-cost ratio. As general guidance:
- For lightweight models and non-model components, CPU inference (e.g. with Intel AVX-512 or AMD EPYC) may be the most economical.
- For moderate workloads, a less expensive GPU like the NVIDIA T4 or L4 may suffice.
- For latency-sensitive workloads, more sophisticated GPUs like A100s, H100/200s, or B100/200s can help reduce response time, though at a higher cost.
Although there is no substitute for comprehensive benchmarking of inference with whatever models (and associated components) are intended for production, there are general guidelines to help identify the best hardware for different workload types:
- High-throughput applications, like batch scoring or recommendation engines, often benefit from high memory bandwidth for rapid data movement and large core count GPUs (or TPUs) that can parallelize workloads efficiently. For use-cases that require even higher throughput than traditional setups, more specialized inference accelerators (e.g., NVIDIA TensorRT, AWS Inferentia) are tuned for throughput at scale; however, these only support specific models types and architectures.
- Low-latency applications, like chatbots or real-time decisioning systems, typically benefit from low memory and interconnect latency, which favor GPUs with low startup and kernel launch latency.
- Multi-modal or large model use-cases, like vision-language models, or LLMs with >7B parameters, require large memory capacity (e.g. >80GB GPU VRAM) to avoid tensor offloading. These use-cases benefit from high-speed interconnects (NVLink, PCIe 5.0) for tensor parallelism or pipeline parallelism across multiple GPUs.
Some public benchmarks are available that assess the performance of different CPU and GPU setups on some common workload types (see MLPerf Inference benchmarks). However, there is no substitute for in-house benchmarking when it comes to assessing the right hardware for specific models and needs. To do this, users can set up a benchmarking framework to measure latency (usually by P50, P95, and P99 percentiles), throughput, and memory usage in scenarios that are representative of usage in production.
Once there is a view of business needs in terms of latency, throughput, and cost limitations, as well as how that inference will be executed, developers can start assessing what hardware setups will meet those requirements. The key is to right-size hardware to actual needs and avoid the ‘bigger is better’ trap. To do this, benchmarking your models on multiple hardware SKUs (e.g. T4 vs A10 vs A100, or Inf1 vs general CPU) can help identify the best performance-to-cost ratio. As general guidance:
- For lightweight models and non-model components, CPU inference (e.g. with Intel AVX-512 or AMD EPYC) may be the most economical.
- For moderate workloads, a less expensive GPU like the NVIDIA T4 or L4 may suffice.
- For latency-sensitive workloads, more sophisticated GPUs like A100s, H100/200s, or B100/200s can help reduce response time, though at a higher cost.
Although there is no substitute for comprehensive benchmarking of inference with whatever models (and associated components) are intended for production, there are general guidelines to help identify the best hardware for different workload types:
- High-throughput applications, like batch scoring or recommendation engines, often benefit from high memory bandwidth for rapid data movement and large core count GPUs (or TPUs) that can parallelize workloads efficiently. For use-cases that require even higher throughput than traditional setups, more specialized inference accelerators (e.g., NVIDIA TensorRT, AWS Inferentia) are tuned for throughput at scale; however, these only support specific models types and architectures.
- Low-latency applications, like chatbots or real-time decisioning systems, typically benefit from low memory and interconnect latency, which favor GPUs with low startup and kernel launch latency.
- Multi-modal or large model use-cases, like vision-language models, or LLMs with >7B parameters, require large memory capacity (e.g. >80GB GPU VRAM) to avoid tensor offloading. These use-cases benefit from high-speed interconnects (NVLink, PCIe 5.0) for tensor parallelism or pipeline parallelism across multiple GPUs.
Some public benchmarks are available that assess the performance of different CPU and GPU setups on some common workload types (see MLPerf Inference benchmarks). However, there is no substitute for in-house benchmarking when it comes to assessing the right hardware for specific models and needs. To do this, users can set up a benchmarking framework to measure latency (usually by P50, P95, and P99 percentiles), throughput, and memory usage in scenarios that are representative of usage in production.
Scaling
When deploying AI applications, it is important to understand how the workloads that the application will need to support will change dynamically over time in order to ensure the system can support business requirements as those workloads change. Real-time applications can vary widely in the magnitude of incoming requests at any given time, potentially even in the timespan of seconds or minutes. Understanding load patterns helps right-size the infrastructure needed to support business requirements, whether they are requirements around latency, throughput, or resource utilization.
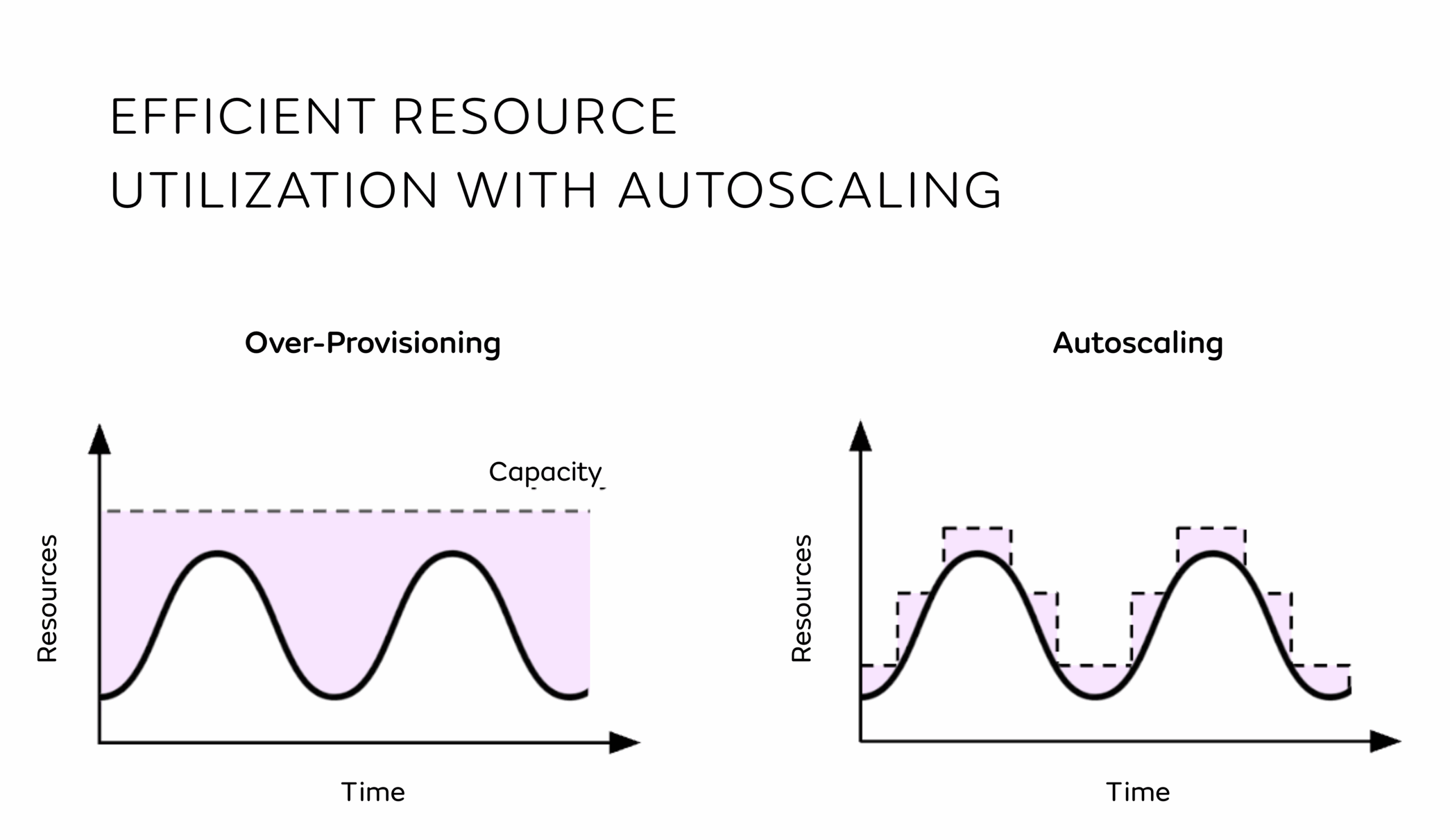
When traffic varies over time, implementing scaling logic on the infrastructure side is key to ensuring that just the right amount of resources needed (i.e., memory and compute) are used. Without scaling logic implemented, users often over-provision resources to guarantee performance metrics are met. This, however, leads to wasted resources (and associated costs) when traffic is not at its peak. In CAST AI’s most recent analysis, for companies with Kubernetes clusters using more than 50 CPUs, “only 10 percent of provisioned CPUs and 23 percent of Memory is utilized“[4]. For companies paying up to millions per month in infrastructure costs, this represents significant potential for cost savings.
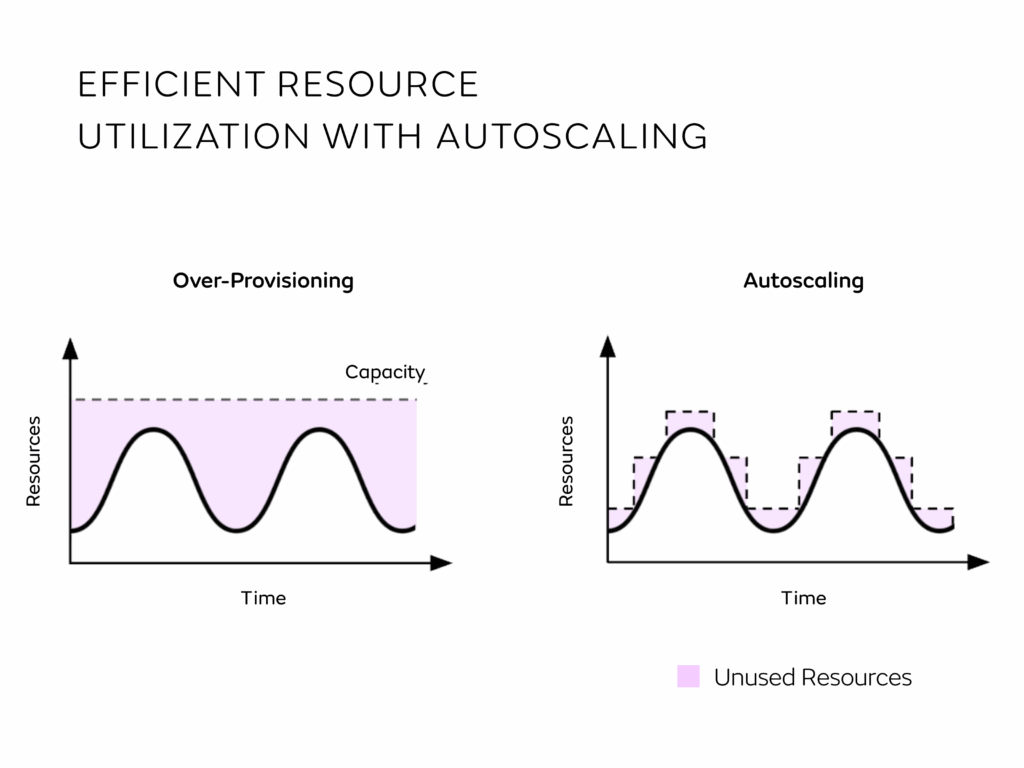
Setting up autoscaling logic allows users to target specific metrics that would automatically trigger scale-up and down events, whereby the components of an application are scaled horizontally. Usually, those metrics are based on performance metrics like latency (aggregated over a certain number of requests) or resource usage like CPU or Memory Utilization.
The way this is implemented depends on the higher-level approach taken to infrastructure orchestration, which generally offers support for scaling logic, as well as rolling updates, service discovery, and fault tolerance. Kubernetes has become the de facto standard for container orchestration, offering this functionality for large enterprise use. As of 2024, over 60% of enterprises have adopted Kubernetes in production environments, with projections suggesting adoption could exceed 90% by 2027 [5]. If using Kubernetes, common approaches to setting up autoscaling include Horizontal Pod Autoscaler (HPA) or KEDA.
Monitoring and Cost Governance
A robust MLOps strategy requires an approach to understanding and managing costs. To support this, centralized AI teams generally implement a dedicated system for monitoring and governance. This way, teams are able to track compute usage in detail (e.g., GPU/CPU hours, memory footprint, request volume, and model response times) with attribution across teams, projects, and/or environments. Cloud-native observability stacks (for example, Prometheus and Grafana) can be extended to record cost metadata alongside performance metrics, while FinOps tools like AWS Cost Explorer or GCP Billing with label-based cost allocation provide a clear breakdown of spend per deployment for cloud implementations. By combining these data streams, teams can set budgets for each production model and configure automated alerts when request volumes or runtime costs spike unexpectedly, helping catch runaway usage early.
With this visibility in place, the next step is implementing automated cost controls directly in the serving and scaling infrastructure. Quotas can cap the maximum concurrent requests or scale-out instances a model can use, preventing runaway autoscaling during traffic surges. Alerts can feed into operational workflows (e.g., routing to cheaper implementations when costs spike). Fallback strategies may include routing non-critical traffic to batch-processing queues or caching common responses to reduce inference calls. Integrating these policies into the CI/CD pipeline ensures every model deployment is evaluated for both performance and cost efficiency before going live, if performance regression tests are expanded to include cost regression checks. This closed-loop approach ensures live operations are governed not just by latency SLAs but also by total cost of ownership, keeping production AI both responsive and economically sustainable.
Cost-Efficient AI with Seldon Core 2
As AI adoption continues to accelerate, addressing the cost challenges of running production AI systems is emerging as a critical priority for organizations running AI at scale. At these levels of scale, inference costs dominate the lifecycle costs of AI, and without deliberate strategies to manage costs, organizations risk runaway infrastructure bills.
Core 2 is designed to address these challenges directly. Our modular, data-centric architecture enables teams to right-size deployments, apply dynamic batching and routing, and integrate autoscaling policies that reduce waste without sacrificing performance. With built-in observability and compatibility with modern FinOps practices, Seldon’s products help organizations monitor usage, set budgets, optimize inference execution, and enforce cost controls seamlessly within their existing workflows. The result is a production environment where AI can scale responsively, remain compliant, and deliver business value, without spiraling infrastructure costs.




