
Many companies are using data to drive their decisions. The aim is to remove uncertainties, guesswork, and gut feeling. A/B testing is a methodology that can be applied to validate a hypothesis and steer the decisions in the right direction.
In this blog post, I want to show how to create a containerized micro-service architecture that is easy to deploy, monitor and scale every time we run A/B tests. The focus will be on the infrastructure and automation of the deployment of the models rather than the models themselves. Hence, I will avoid explaining the details of the model design. For illustration purposes, the model used is one created in this post by ML Engineering Director, Alejandro Saucedo. The model performs text classification based on Reddit moderation dataset. How the model is built and how it works is described in the original post.
In case you already know how A/B testing works, feel free to jump to the A/B Testing in Kubernetes with seldon-core section.
What is A/B testing?
A/B testing, at its core, compares two variants of one variable and determines which variant performs better. The variable can be anything. For instance, for a website, it can be the background color. We can use A/B testing to validate if changing the background color invites the users to stay longer on the website. For recommendation engines, it can be whether changing the model parameters generates more revenue.
A/B testing has been used since the early twentieth century, to improve the success of advertisement campaigns. Afterward, A/B testing has been used in medicine, marketing, SaaS, and many other domains. Notably, A/B testing was used in Obama’s 2012 campaign to increase voters’ donations.
How Does A/B Testing Work?
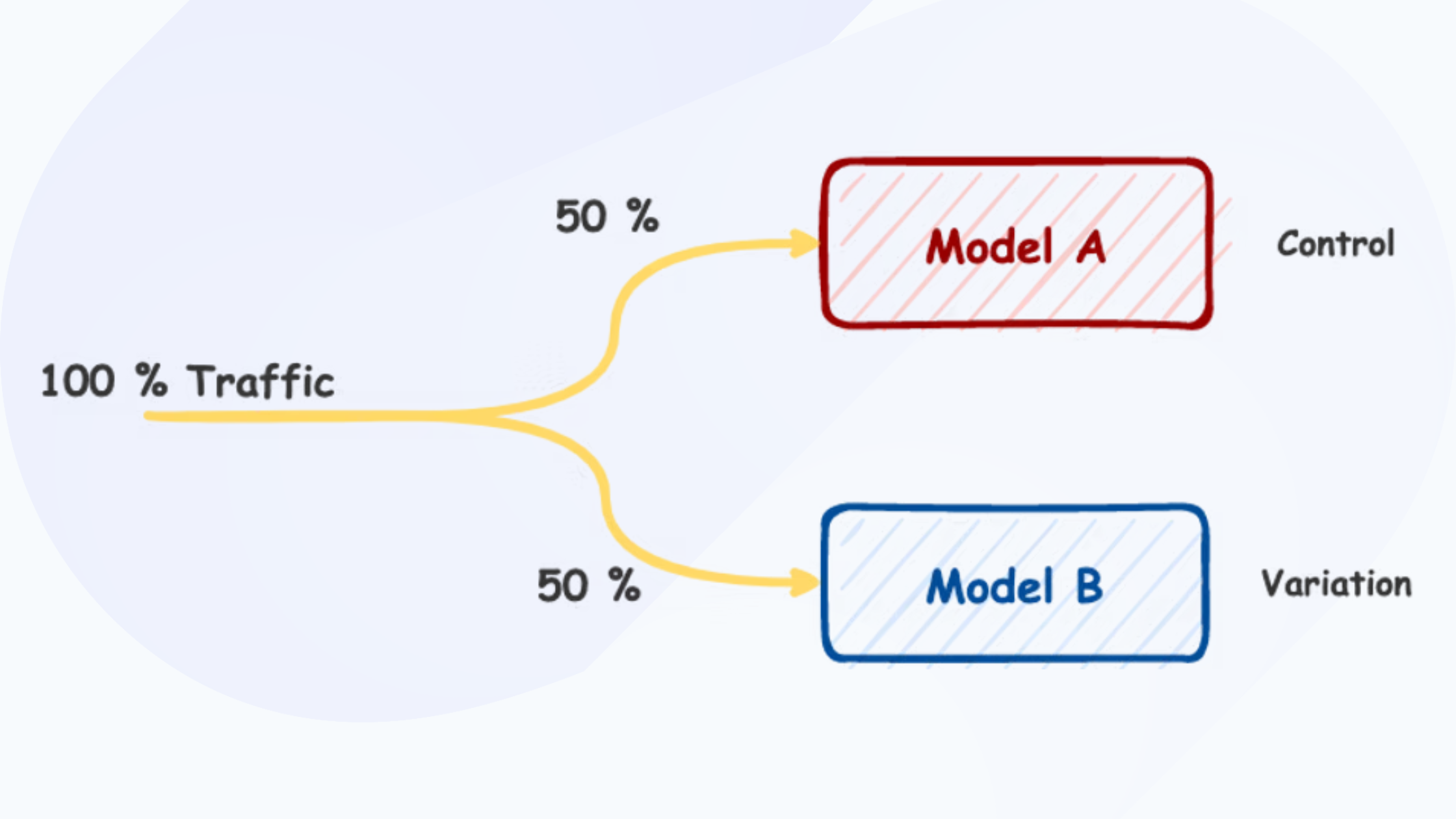
To run A/B testing, you need to create two different versions of the same component, that differ on only one variable. In the case of selecting the most inviting background color for our website, version A is the current color (e.g. red), also known as Control, and version B is the new color (e.g. blue), called Variation. Users are randomly shown either version A or version B.

Before we can pick the better performing version, we need a way to objectively measure the results. For this, we have to choose (at least) one metric to analyse. A meaningful metric in this example would be user session duration. Longer sessions mean users are using the website more. In our analysis, we search for the variation with longer user sessions. If we are happy with the results, we can choose to deploy this version to all the users.
How does A/B testing apply in Machine Learning
In Machine Learning, as almost in every engineering field, there are no silver bullets. We need to test to find a better solution. Searching for the data science technique that fits our data best, means we have to test many of them. To optimize the model, we need to play with many parameters or parameter sets.
A/B testing is an excellent strategy to validate whether a new model or a new version outperforms the current one. All this while testing with the actual users. The improvements can be in terms of F1 score, user engagement, or better response time.
A/B Testing Process
Let’s consider the case when we want to test the model’s performance. To run A/B testing, we need to:
- Define the hypothesis. In this step, we decide what is it we want to test. In our case, we want to test whether the new model version provides faster predictions.
- Define metric(s). To pick the better version in the test, we need to have a metric to measure. In this example, we will measure the time spent from the user’s request arrival until it gets a response.
- Create variant. Here we need to create a deployment that uses the new model version.
- Run experiment. After preparing the variant, we can run the experiment, ideally for a defined time frame.
- Collect data. At the same time, we must be collecting the data needed to measure the metric(s) from 2.
- Analyze results. All that is left now is to analyze the data and pick the variant that yields better results.
A/B Testing in Kubernetes with seldon-core
Kubernetes is the default choice for the infrastructure layer because of its flexibility and industry-wide adoption. We can provision resources dynamically based on the tests we want to run, and release them once the testing phase is finished.
In the MLOps space, there are not many open-source tools that support A/B testing out-of-the-box. Seldon-core is the exception here and it:
- supports Canary Deployments (configurable A/B deployments)
- provides customizable metrics endpoint
- supports REST and gRPC interfaces
- has very good integration with Kubernetes
- provides out-of-the-box tooling for metric collection and visualization (Prometheus and Grafana)
Therefore, choosing seldon-core for model deployment is not a difficult decision.
Resources used in this post are in this GitHub repository.
What Tooling is Needed
The architecture we are aiming for looks as follows:

- Ingress Controller — makes sure requests coming from the users reach the correct endpoints. The ingress controller concept is described in great detail in the Kubernetes documentation. We will be using ambassador as an ingress controller since it is supported by seldon-core. Other alternatives are Istio, Linkerd, or NGINX.
- Seldon-core — as mentioned above, will be used for serving ML models as containerised microservices and for exposing metrics.
- Seldon-core-analytics — is a seldon-core component that bundles together tools to collect metrics (Prometheus) and visualise them (Grafana).
- Helm — is a package manager for Kubernetes. It will help us install all these components.
Building the models
To compare the two model versions, we first need to have the model versions.
In the test, we want to find which model version is better. The better model version for this case is defined as the one that provides predictions faster. For demonstration purposes, the only difference between the two versions will be an artificial delay added to version A before returning the response.
Let’s start by cloning the repository:
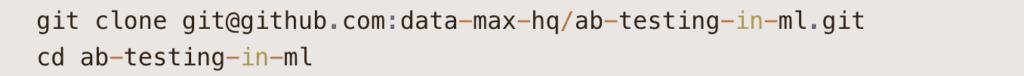
Build the version A:

Now, let’s build the version B:

Setting up
After preparing the container images, let’s get started with the deployment. We will assume that we have a Kubernetes cluster up and running. The easiest way to get a Kubernetes cluster is to set up a local one with minikube, kind, or k3s.
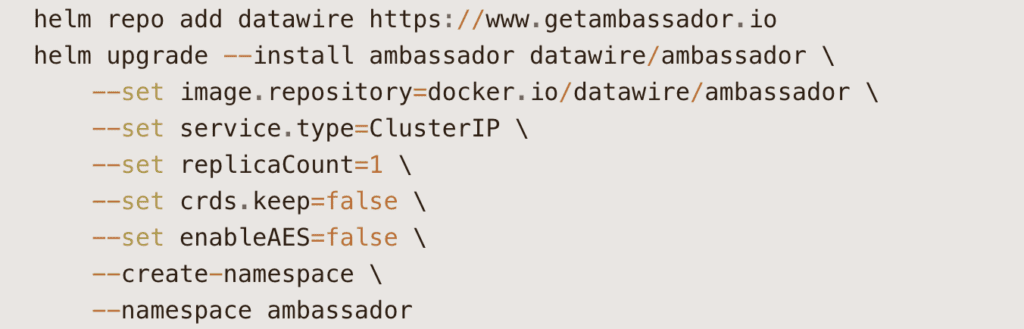
Initially, we will install the helper components. We start with the ingress controller:

Next, we will install seldon-core-analytics:


The next step is to install Seldon-core:

This step, among other things, installs the necessary custom resource definitions (CRDs) in our cluster, needed to have SeldonDeployment working.

Up to this point, we have installed the necessary components for our infrastructure. Next, we need to bring this infrastructure to life with the actual microservices that we want to test.
Deploy ML models as microservices
The next step is deploying both versions of our ML models. Here, we will use a canary configuration of a SeldonDeployment resource. A canary configuration is a setting where two (or more) versions are deployed and they will receive parts of the overall traffic. The Kubernetes manifest file looks like this:

After this deployment, we have the complete architecture up and running.

In our code, we have created a custom metric that reports the time until the prediction for every request. In addition, we have added a tag to be able to track each prediction from which version it was generated.

Let’s now test whether the deployment works. First, we will port-forward the ambassador port, to send requests directly from our machine:

and then we will send a request:

Inspecting the response we can see:
- In the data.ndarray key, we get the prediction.
- In the meta.metrics and meta.tagskeys, we get the custom metrics defined above.
- In the meta.requestPath key, we can see the model(s) that handled this request.

Finally, we need to build a dashboard to visualise the collected metric. We start by port-forwarding Grafana, to make it reachable from our machine:

We will create the dashboard, or import one already prepared from here.
After the dashboard is created, we have the deployment and the monitoring ready.
Now, let’s generate some load. The seldon_client/client.py script in the repo uses the seldon-core python client to send a few thousand requests.

We can now see values visualised in our dashboard and can compare the model versions on the prediction response time basis.
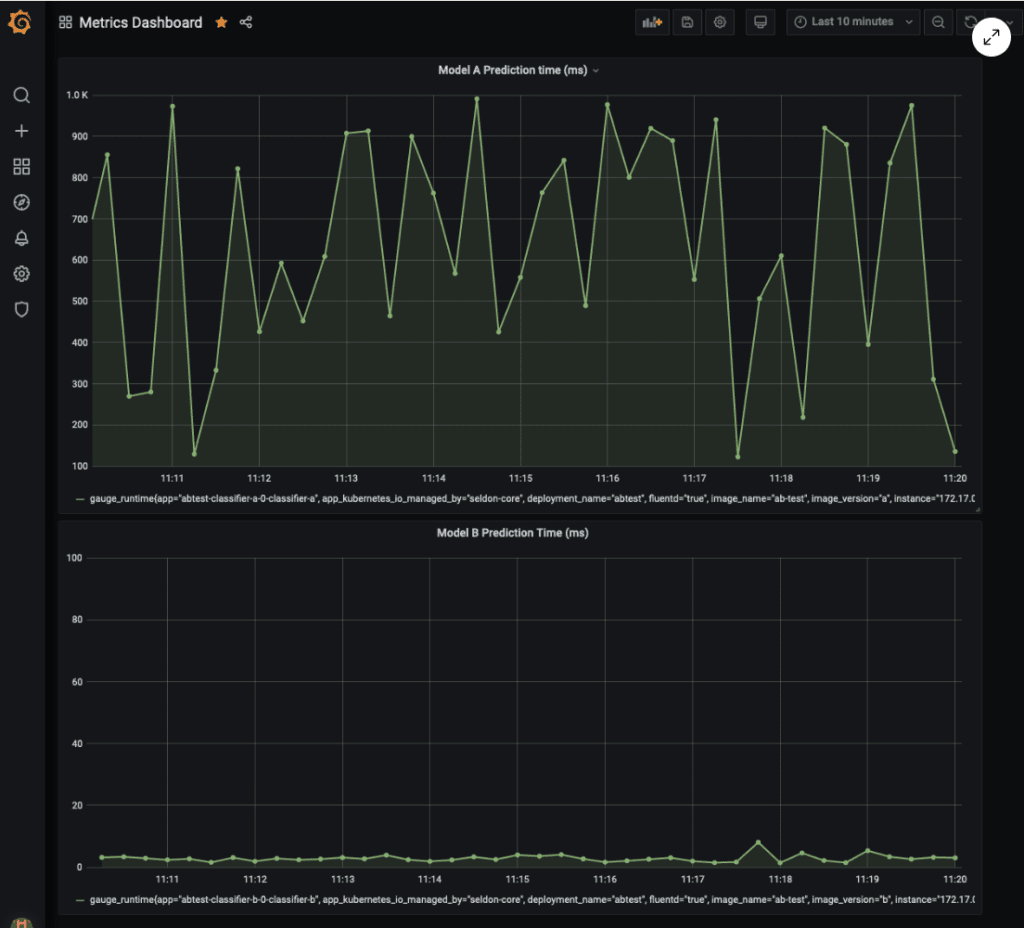
Unsurprisingly, the model version B, without the artificial delay, responds faster.
What’s next?
In real life, choices are not always binary. More often than not, we have to consider more options. To address this, we can use Multi-armed Bandits (MAB). MAB are A/B/ tests that update in real-time based on the performance of each variation. MABs are supported on seldon-core as well.
Summary
With this demo, we were able to set up all the necessary infrastructure for A/B testing, collect and visualize metrics, and in the end, make an informed decision about the initial hypothesis. We also have the option to track further metrics using the custom tags we added in the response.
Sadik Bakiu, CEO and Principal Data/ML Engineer at Data Max, is one of our Slack community champions! Join him and over 2,500 other MLOps professionals on Slack. Get support and collaboration around all things ML as well as Seldon open source and core products. Seldon’s Head of DevRel, Ed Shee, hosts bi-monthly community calls every first and third Thursday.
Sadik’s company, Data Max works hard to bring state-of-the-art machine learning solutions to their customers. Implementing such solutions enables their customers to make informed decisions and become truly data-driven. Learn more about Data Max here. You can also find Data Max’s Github by clicking here.





