
Large Language Models (LLMs) like GPT-4 and Llama 2 have opened up new possibilities for conversational AI. Companies worldwide are eager to build real-world applications leveraging these powerful models. However, taking LLMs into production introduces a unique set of challenges based on the size and complexity of these models. In this comprehensive blog series, we’ll explore (1) the components of LLM applications, (2) deployment tradeoffs, and (3) techniques to orchestrate LLMs in production. With these ideas in mind, you should be equipped to perform scalable, efficient, guided inference with built-in monitoring and debugging.
In this post, we’ll dive into the different elements comprising LLM applications.
LLM Applications and Use Cases
LLMs have opened up a new class of enterprise use cases. Being trained on such a large amount of information, these models provide a strong foundation to build off. This makes them incredibly versatile and easily adaptable to suit a variety of applications. Whether leveraging the built in knowledge of the model or fine-tuning to your use case, there are many ways to provide a useful and intuitive user experience.
Some examples of LLM applications include:
- Chatbots: Provide customer support, product recommendations, and conversational search
- Document understanding: Summarize reports, extract key information, and analyze sentiment
- Code completion: Explain and document code, suggest improvements, and auto-generate code
- Content generation: Write blog posts, emails, ad copy, and outlines based on prompts
- Search: Answer natural language questions on top of a large collection of texts
- Translation: Translate between languages, and perform style transfer to change the tone and reading-level
New capabilities emerge regularly as models grow stronger. LLMs make it possible to quickly prototype, but can become increasingly complex as more components are added to enhance the functionality and accuracy of the outputs.
LLM Components and Reference Architecture
The reference architecture of an LLM application has begun emerging over recent months. Depending on the use case and requirements, the following components can be composed together to build an application:
LLM Model
The LLM model is the heart of the LLM application and selecting a model depends on a variety of factors. The primary elements are the size of the model (# of parameters) and whether it is open sourced or behind an API. Some models may have tokenizers and embedding models built in, while others will require you to run these steps yourself. Tokenizers split input text into smaller chunks, while embedding models convert the text into numeric vectors which can be understood by an LLM.
The easiest place to begin prototyping is with OpenAI’s GPT-4, as it is quick to get up and running given how adaptable the model is. In some cases, a long context window may be required if performing a lot of in-context learning, making Claude 2 an excellent choice. However, when using such large models, both the cost and latency could become prohibitive.
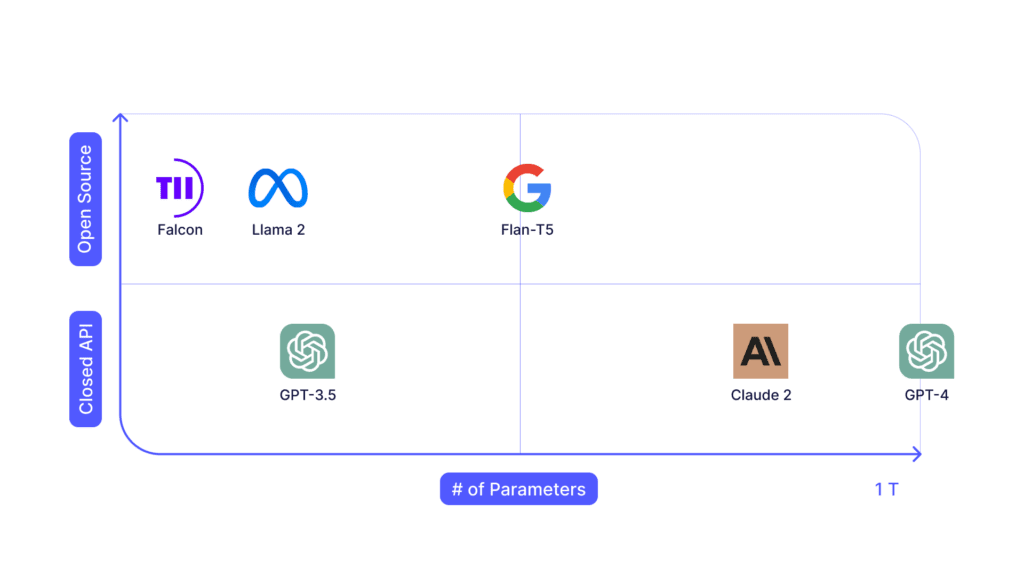
GPT-3.5 is 20X cheaper for input tokens, 30X cheaper for output tokens, and runs significantly faster. This incentivizes the developer to squeeze as much accuracy out of their prompts as possible to leverage GPT-3.5 over GPT-4 as their application scales. Prompt engineering can only get you so far, and at some point you may choose to instead fine-tune your use case on top of an open source model like Meta’s LLama 2. Taking this approach comes with significantly more complexity in terms of the training and deployment. However, if done correctly, it can potentially reduce costs and latency while improving task accuracy.
Prompt template
Much like the experimentation process that has evolved in traditional Machine Learning model training, prompt engineering has emerged as a core activity in LLM application development. There are several prompting techniques that lead to better results. The first technique is to write clear instructions and specify the steps required to complete the task. Most tasks can be done using a “zero-shot” prompt, but adding some examples with a “few-shot” prompt can further improve and tailor the response. Even simply including phrases such as “show your work” or “let’s think step by step” leads the model to iteratively develop a solution, increasing the chances of a correct answer. This “chain-of-thought” prompting is even more powerful if a few examples of reasoning logic are provided.

Prompts can then be templated and reused by an LLM application. They can be integrated into your code with a simple f-string or str.format(), but there are also libraries like LangChain, Guidance, and LMQL that offer more control. For chat completion APIs, there is generally a system prompt to assign the task, followed by alternating user and assistant messages. You can seed the chat with examples of user questions and assistant answers before running it. Experimenting and iterating on these prompt templates in a structured way will lead to improved model performance. The outputs of the model should be evaluated by either a scoring function or human feedback.
Vector database
Many use cases will require access to information that the LLM has not been trained on. This may be a private knowledge base (e.g. a company wiki), recent information (e.g. events this weekend), or a specific document (e.g. a research paper). There might be other cases where the context window of the model is too small to include everything in the prompt (e.g. an entire book). Adding an external database can provide access to supplementary information in a technique known as retrieval augmented generation (RAG).
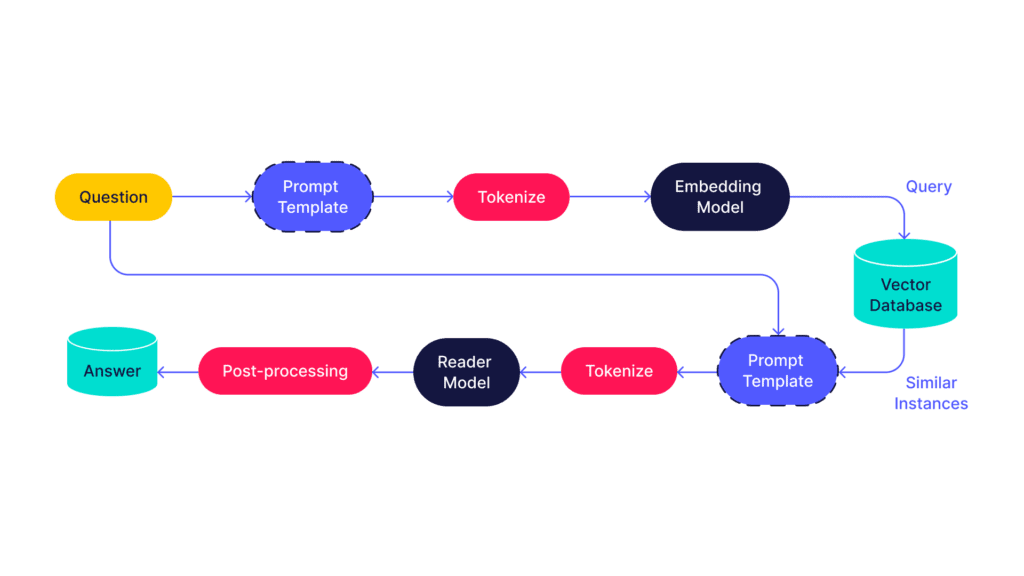
Vector databases have been around for some time, but have surged in popularity recently as they make their way into LLM applications. Relevant external information is first chunked into blocks (e.g. sentences or paragraphs), tokenized, and run through an embedding model. These are then fed into a vector database, such as Pinecone, Chrome, Qdrant, or pgvector (open source). When a prompt is made, it is also vectorized and a similarity search is performed to retrieve relevant entries from the database. These entries are then fed in alongside the original prompt, providing the context needed to provide a coherent response. The LLM may cite which chunks it used in its response, which adds a degree of trust to counteract potential hallucinations.
Agents and tools
Using LLMs alone can enable powerful applications, but there are inherent limitations. For example, they cannot continually prompt themselves, make external API calls, nor retrieve a web page. An LLM agent has access to tools that can perform actions beyond text generation. For example, an LLM agent could perform a web search, execute code, perform a database lookup, or do maths calculations. OpenAI language models can decide which tools to use (called functions) and return a JSON object with the arguments to call the function. This enables a whole new suite of use cases, such as booking a flight, generating an image, or sending an email.
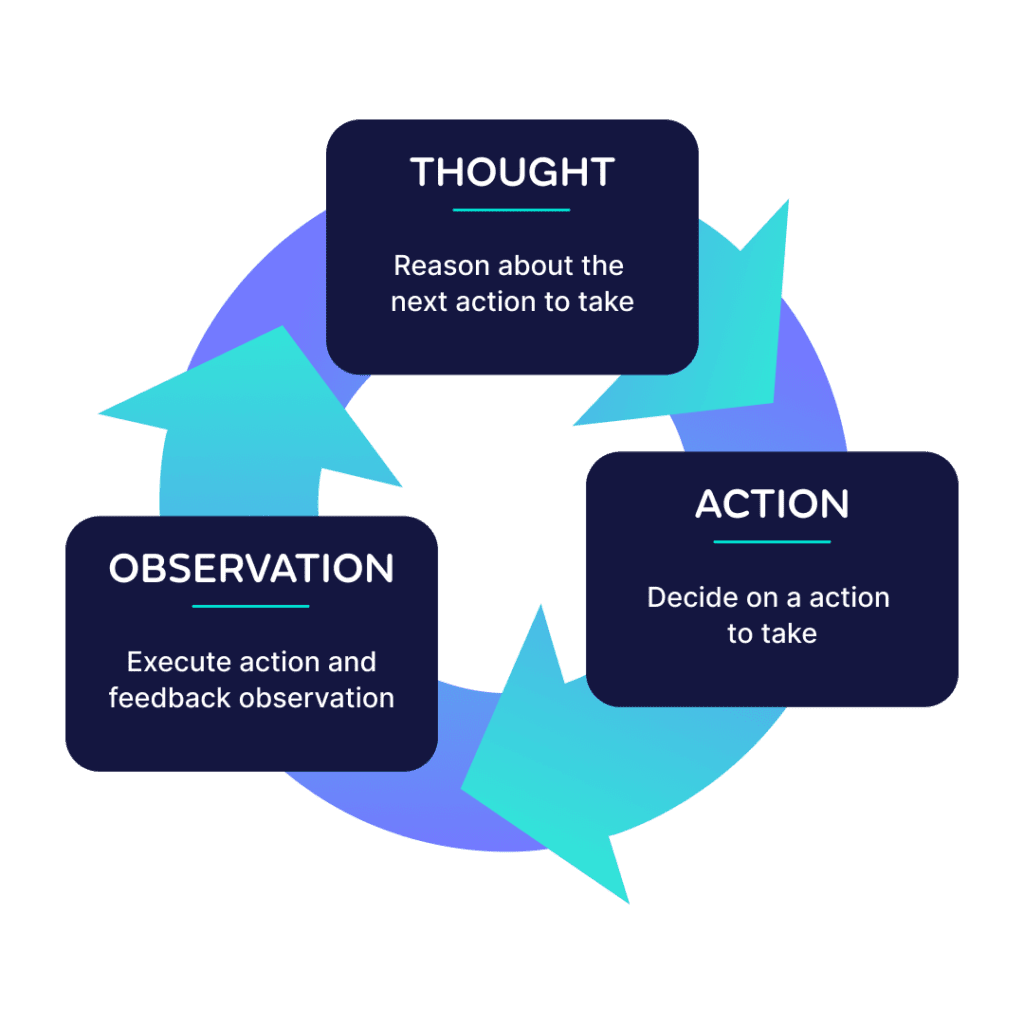
Some frameworks enable agents to execute iteratively to complete a task. This could be as simple as breaking down a task into several subtasks, or “self-asking” to continue gathering relevant information for the task. These can then be executed in a chain to iteratively work towards a correct answer. The idea of combining this reasoning alongside taking actions using tools led to the emergence of a framework called ReAct. ReAct enters a loop of thinking which action to take, taking that action, observing the result, and deciding on a subsequent action until a solution is found. Although this approach has proved to outperform baseline LLMs, it should be noted that evaluating the performance of these systems and achieving reliable results is still a major challenge. Security is also a concern as LLMs are given the ability to take actions, such as posting on the web.
Orchestrator
Orchestrators, like LangChain and LlamaIndex provide a framework to tie these components together. They create abstractions on top of LLMs, prompt templates, data sources, agents, and tools. Templating frameworks like Guidance and LMQL enable complex prompts that specify inputs, outputs, and constraints. In addition, these tools can improve performance by providing memory management, token healing, beam search, session management, error handling, and more. Being able to create a logical control flow on top of LLMs enables developers to build differentiated, specialized, and hardened use cases. Orchestrators and guiding frameworks will be covered in Part 3 of this blog series.
Monitoring
Given the stochastic nature and rapid evolution of LLM models, your application should be monitored in production. Standard monitoring of CPU, GPU, memory usage, latency, and throughput should be tracked. Drift and outlier detectors can also be deployed to alert you of changing or anomalous inputs over time. Requests and responses should also be logged so that unexpected or harmful outputs can be evaluated. With complex chains, or graphs, of LLM agents strung together, it can be difficult to track exactly how the prompt is evolving. Tools like LangSmith and Seldon Core v2 provide the ability to trace the flow of data, providing visibility into the behavior of your LLM application. Not only that, but Seldon Core v2 provides a data-centric deployment graph that enables advanced monitoring with drift detectors and explainers. Monitoring will be discussed more in Part 3 of this series.
In Part 1 of this series, we investigated emerging LLM use cases, and the components used to build them. Look out for Part 2 of this series (Deploying LLMs in production: LLM Deployment Challenges), where we will dive into the challenges and best practices associated with deploying an LLM application. In Part 3, we will explore LLM orchestration and monitoring.




