In our earlier blog posts in this series, you’ve explored an overview of LLMs and a deep dive into the challenges in deploying individual LLMs to production. This involves striking a balance between cost, efficiency, latency, and throughput–all key elements for achieving success with AI.
In this blog post, we will discuss some of the key challenges in building a full production application that is utilizing LLMs. One area we won’t focus on is fine-tuning – we will assume you have modified a foundation model to your particular use case and can deploy it as part of a wider application.
Let’s dive into an example of a document question answering system. To help you get a clearer picture, the diagram below show how the data flows through the system:
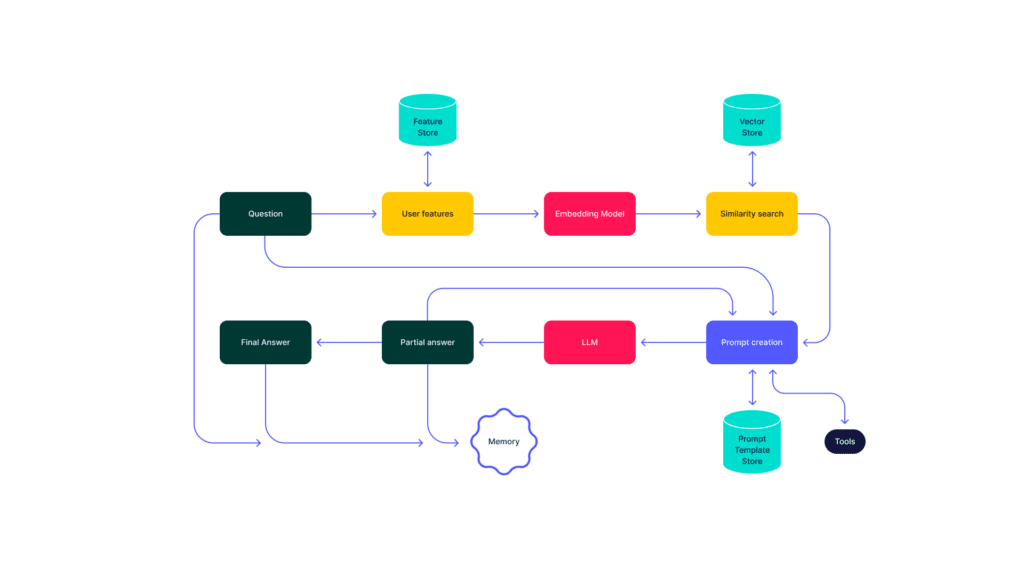
Data Flows Explained
The above flow can be summarized as follows:
- A question comes in from a user.
- Then, we add any meta data to the request by calling a feature store to get details about the user.
- Next, call an embedding model on the question to get one or more vectors.
- Now, we do a similarity search against a vector store holding vector representations of internal documents to find some set of candidate documents.
- Once we have several useful documents, we mix them with the original question and construct a prompt. With the query in hand, we call our LLM and get an answer back.
- After that, we decide if this answer is the final answer or we need to call again the language model, perhaps with an altered prompt, while saving the state as we proceed in the loop.
- Finally, when we’re confident in the result, we eventually return a final answer to the user.
LangChain
As you can tell, a variety of tools are needed to provide a final application. The most popular tool to solve this at present is LangChain, which provides a one stop shop to manage:
- LLMs (local or via APIs)
- Prompt templating techniques
- Vector stores
- Feature Stores
- Memory and state management
- Agents and tools
Although powerful, LangChain has some challenges when using it to move your application to production. Given it provides a large matrix of options, each of which need to work together, there can be unexpected problems when tools do not play nicely together or the defined logic has some unexpected assumptions. Some people have discussed these and provided simpler alternatives for part of the story such as simpleaichat (following a blog post by the author) and minichain.
Guided Prompting
For the purposes of this discussion we will focus on one key sub-area, guided prompting. Guided prompting refers to the core process of directing the LLMs to solve your task for one or more requests while at the same time ensuring the model generates outputs in accordance with your existing knowledge and constraints.
There are two interesting projects in this area we shall discuss: Guidance and LMQL.
Guidance
Guidance provides a templating language using the handlebars templating to allow a prompt to be incrementally completed with associated restrictions on the parts filled in by the language model. An example from their docs is shown below where a proverb is generated with certain restrictions:


The Guidance program can take parameters which are filled in as well as defined slots where generation takes place (with constraints).
We will highlight two interesting capabilities. Firstly, Guidance if used with a local model can take advantage of key-value (or KV) caching of attention computations to ensure optimized inference is done by not repeating computations when prompts that have already been processed are used again in further generation. An example they use to illustrate this is filling in a character definition over repeated calls to a model as shown below (generation steps in green):

Another interesting feature is the ability to do token healing. Language models map sequences of characters to individual tokens. There can be tokens that contain subsets of characters contained in other tokens. In their example, they show how a prompt generating a URL generates an invalid sequence when the prompt ends in a colon thus limiting the sequences that can be generated by the model. Guidance can solve this issue by adjusting the prompt. This involves removing the colon from the prompt and ensuring that any token generated starts with a colon as its initial character. By doing this, the model will produce outputs that align appropriately with the intended format. This is shown below:
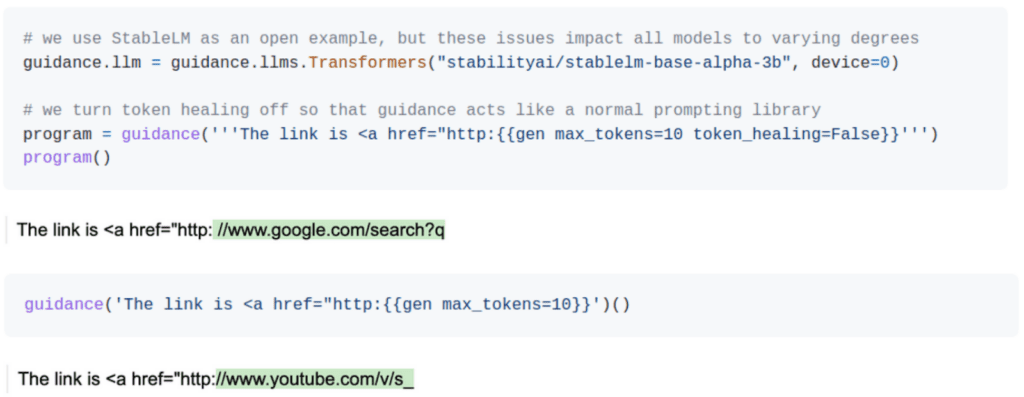
For the above to work like with KV caching it requires a close integration with the inference server.
LMQL
If we move now onto LMQL, it also provides a templating language for guided generation, an example of which is shown below:
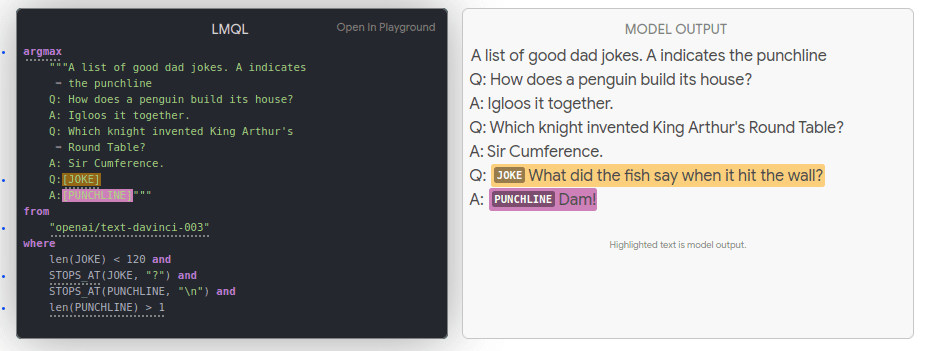
Constraints can be added to the slots where generation is done. This can be seen in the above providing constraints including the length and format of the generated joke and punchline.
One interesting feature of LMQL is the ability to do scripted beam search where you can do a beam search over multiple generation points in the prompt template. Again, this requires quite close collaboration between the guidance engine and the inference server.
Monitoring in Data Flows
Now, let’s move back to the wider application data flow. When placing your application into production the data flow diagram we showed above can be annotated with many points where monitoring is key for ensuring correct and safe operation of the application. This is shown in the diagram below:
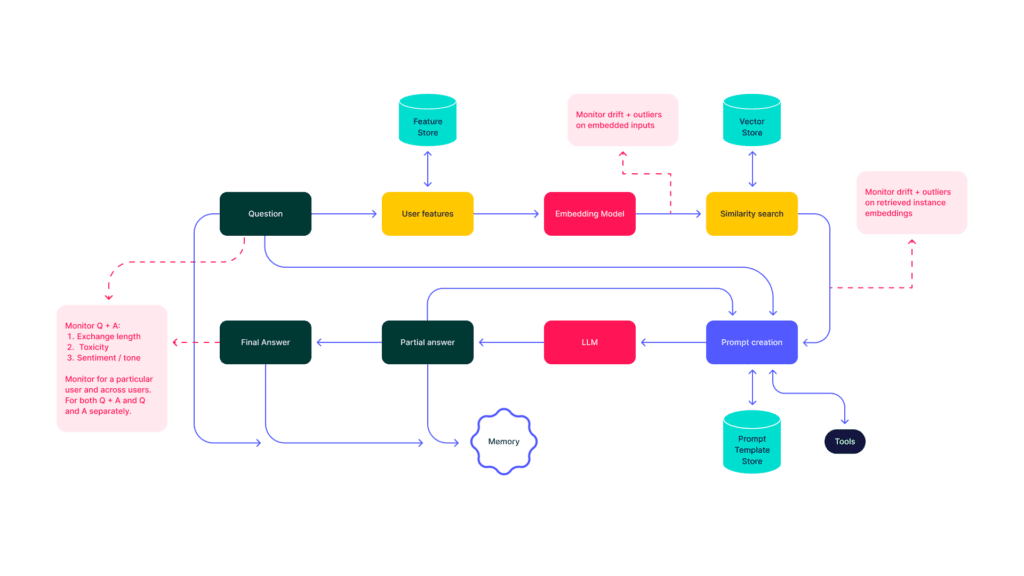
The key areas highlighted are:
- Monitoring for drift and outliers from the question embedding as well as the documents returned by the similarity search.
- Monitoring the question and answer in isolation as well as in combination for things such as: toxicity, sentiment, hallucinations, conversation length.
Many of these could also be combined as part of the real time inference flow to change the output of the individual request if we perceive there are outliers, toxicity or unexpected changes in sentiment.
The data flow paradigm of clearly exposing the data at any point in the transformation steps from question to answer is core to Seldon’s data centric approach to machine learning pipelines as provided by V2 of Seldon Core. The creation of Seldon Core V2 provides the ability to create well defined data flows containing machine learning model as well as monitoring components.
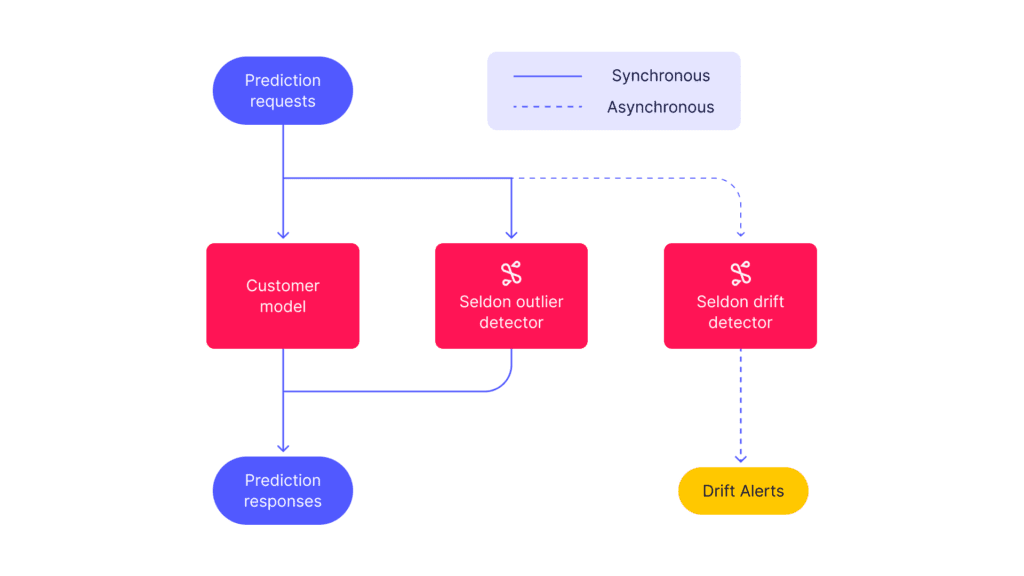
A more API based approach for post-hoc analysis and auditing is provided by LangSmith, the recently created offering from LangChain. Organizations should look to invest in these techniques to ensure their LLM based applications are performing as expected and can be clearly audited.
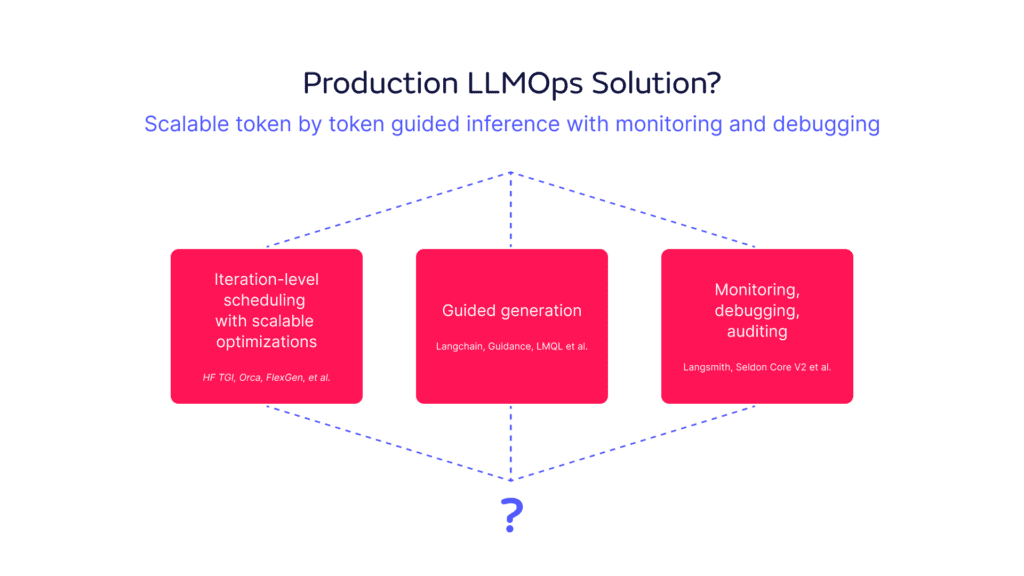
In summary, to bring this blog series to a close to provide production ready LLMs a single sentence take away is:
Scalable token by token guided inference with monitoring and debugging.
The industry still has some way to progress before such a solution is available.