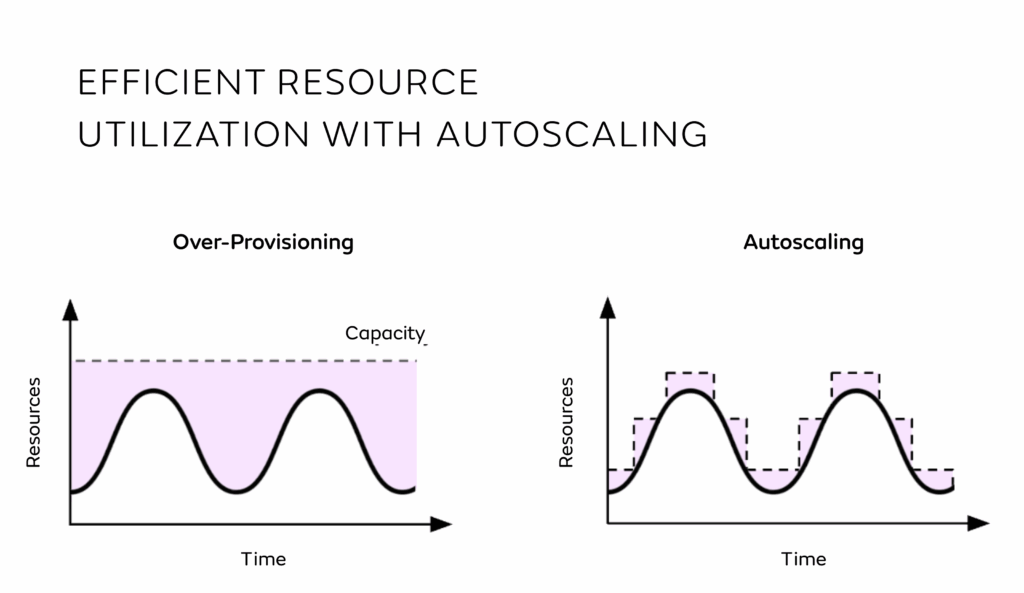
Get your models into production with no wasted spend or unnecessary complexity. With flexible support and modular add-ons, you can scale confidently as your needs evolve.
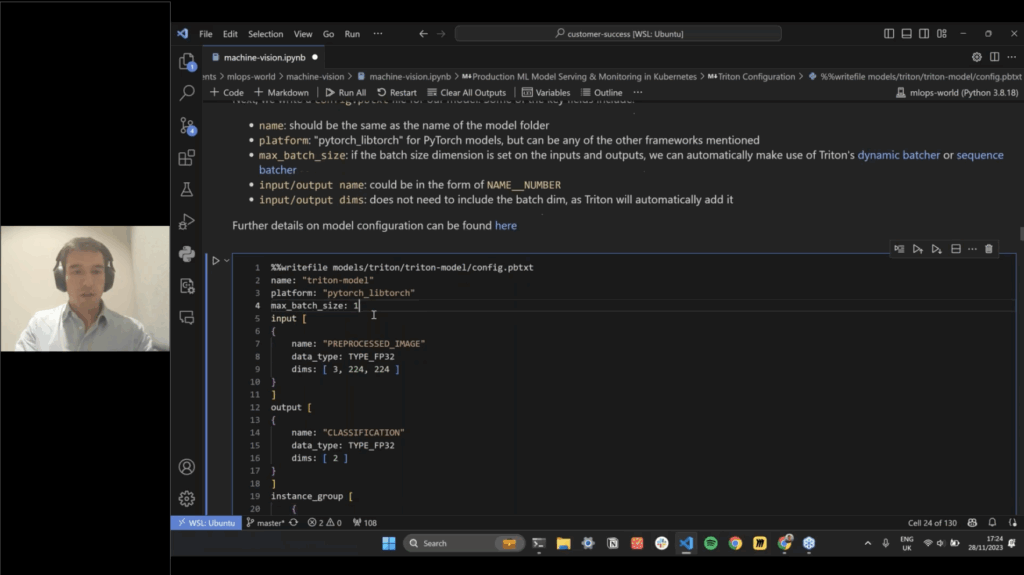
An Open Source lightweight inference server for your machine learning models, built to deploy ML models in simple environments.
Send us a message, and we’ll connect you with the right member of our team.
A Modular framework with a data-centric approach, built to put models into production at scale, especially for data-critical, real-time use cases (e.g., search, fraud, recommendations).
Accelerator programs including hands-on support plus the option to add modules, to ensure your machine learning projects are set up and maintained efficiently.
Accelerator programs including hands-on support plus the option to add modules, to ensure your machine learning projects are set up and maintained efficiently.
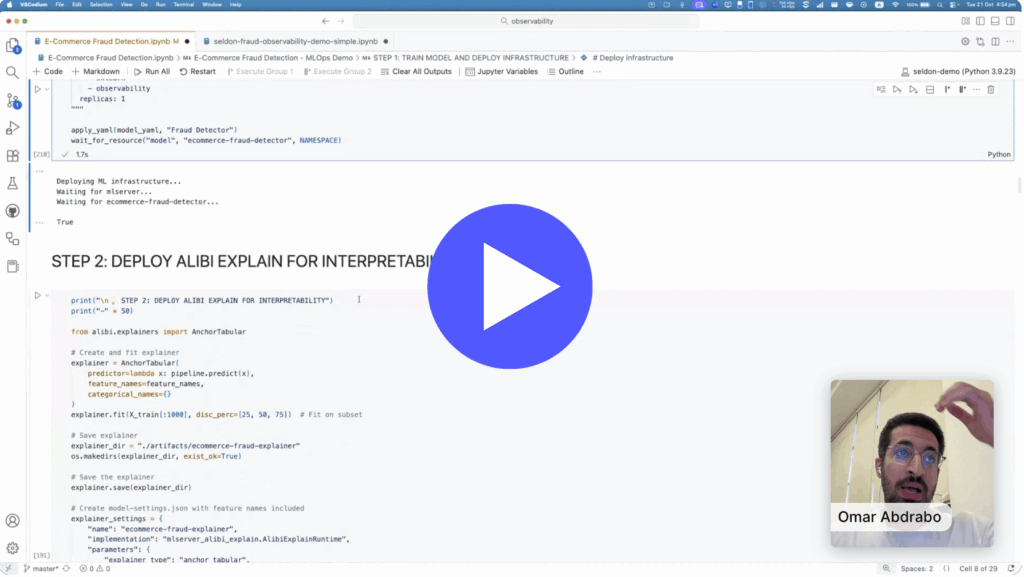
Add powerful explainability tools to your production ML pipelines, including a wide range of algorithms to understand model predictions for tables, images, and text covering both classification and regression.
Includes
Comprehensive Explainability Coverage
Storage and Portability
Benefit from Seldon's Ecosystem
Download Alibi Explain Product Overview
CORE+ Add-On
Add real-time and batch monitoring to your ML pipelines, spotting drift, outliers, and adversarial inputs across all data types. It helps teams boost model quality, build trust, and meet global AI regulations.
Includes
Comprehensive Detection Coverage
Pre-trained Models and Supported Datasets
Model- and Context-Aware Detection
Benefit from Seldon's Ecosystem
Download Alibi Detect Product Overview
CORE+ Add-On
Simplify the deployment, support for common design patterns (RAG, prompting, and memory) and lifecycle management of Generative AI (GenAI) applications and LLMs.
Includes
Deployment with Standardized Prompting
Agents and Function Calling
Embeddings and Retrieval
Memory and State Management
Operational and Data Science Monitoring
Benefit from Seldon's Ecosystem
Download LLM Module Product Overview
CORE+ Add-On
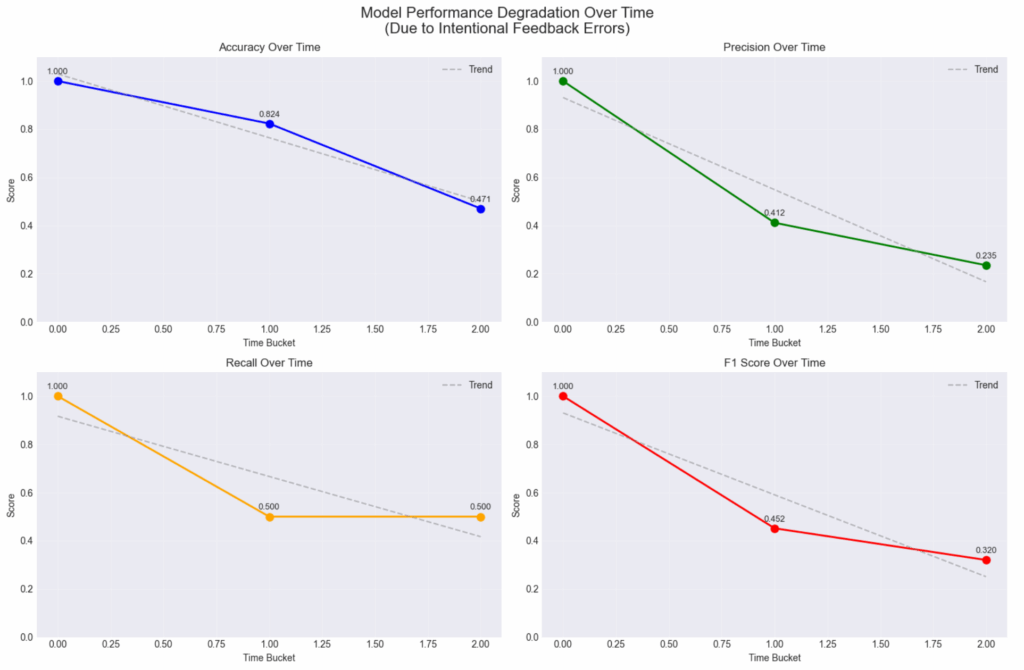
Model Performance Metrics (MPM) Module enables data scientists and ML practitioners to optimize production classification & regression models with model quality insights.
Includes
Comprehensive Metric Coverage
Feedback Storage and Linking
Time-Based Trend Analysis
Model Quality Dashboards
Benefit from Seldon's Ecosystem
Download MPM Module Product Overview
FREE DOWNLOAD
The Essential Guide to ML System Monitoring and Drift Detection
Learn when and how to monitor ML systems, detect data drift, and overall best practices, plus insights from Seldon customers on future challenges.
FREE DOWNLOAD
The Essential Guide to ML System Monitoring and Drift Detection
CONTINUED LEARNING
Explore new perspectives shaping the future of machine learning and AI.
Join over 25,000 MLOps professionals with Seldon’s MLOps Monthly Newsletter. Opt out anytime with just one click.
Email Signup Form
✅ Thank you! Your email has been submitted.
Stay Ahead in MLOps with our Monthly Newsletter!
Email Signup Form
✅ Thank you! Your email has been submitted.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.