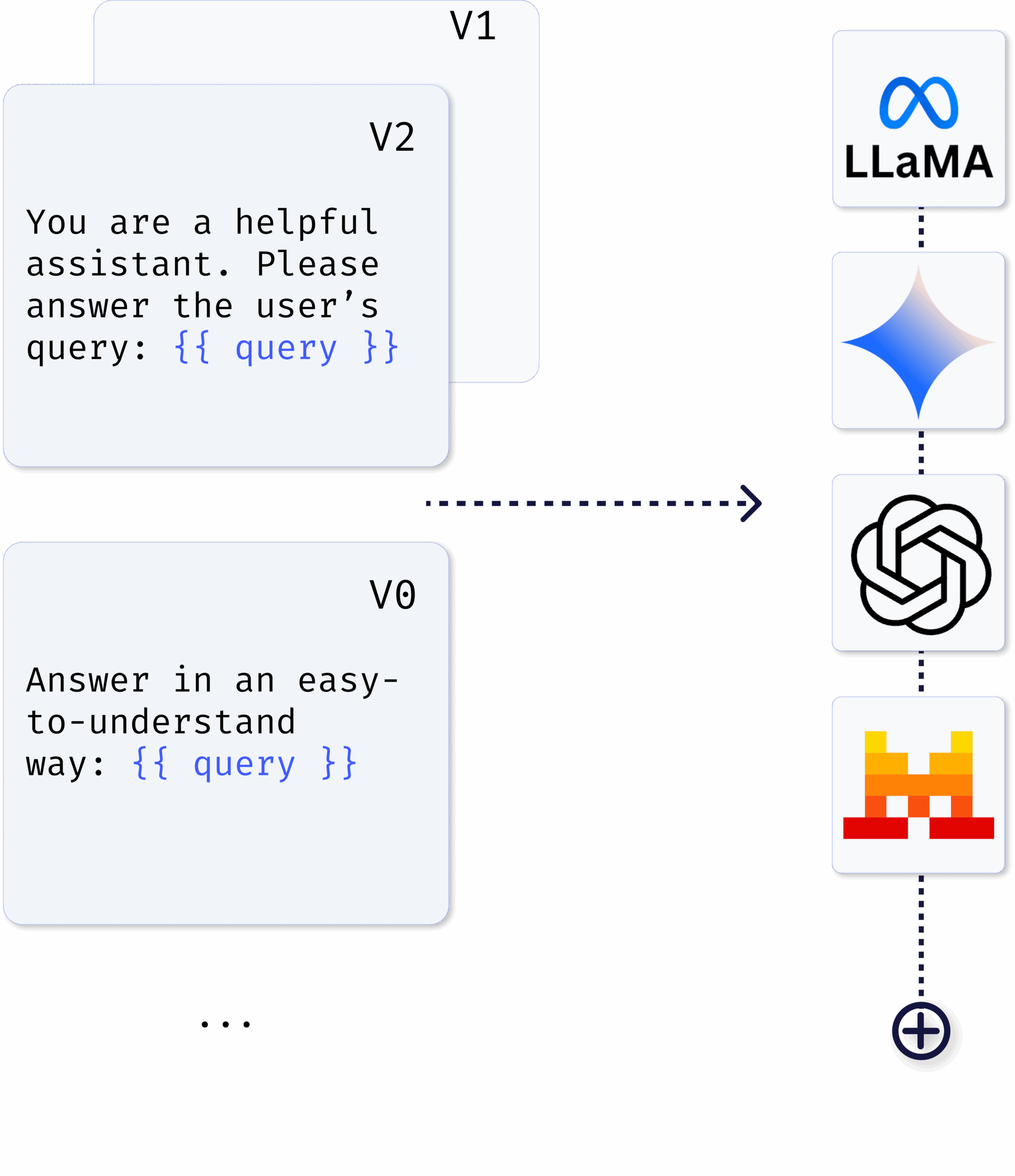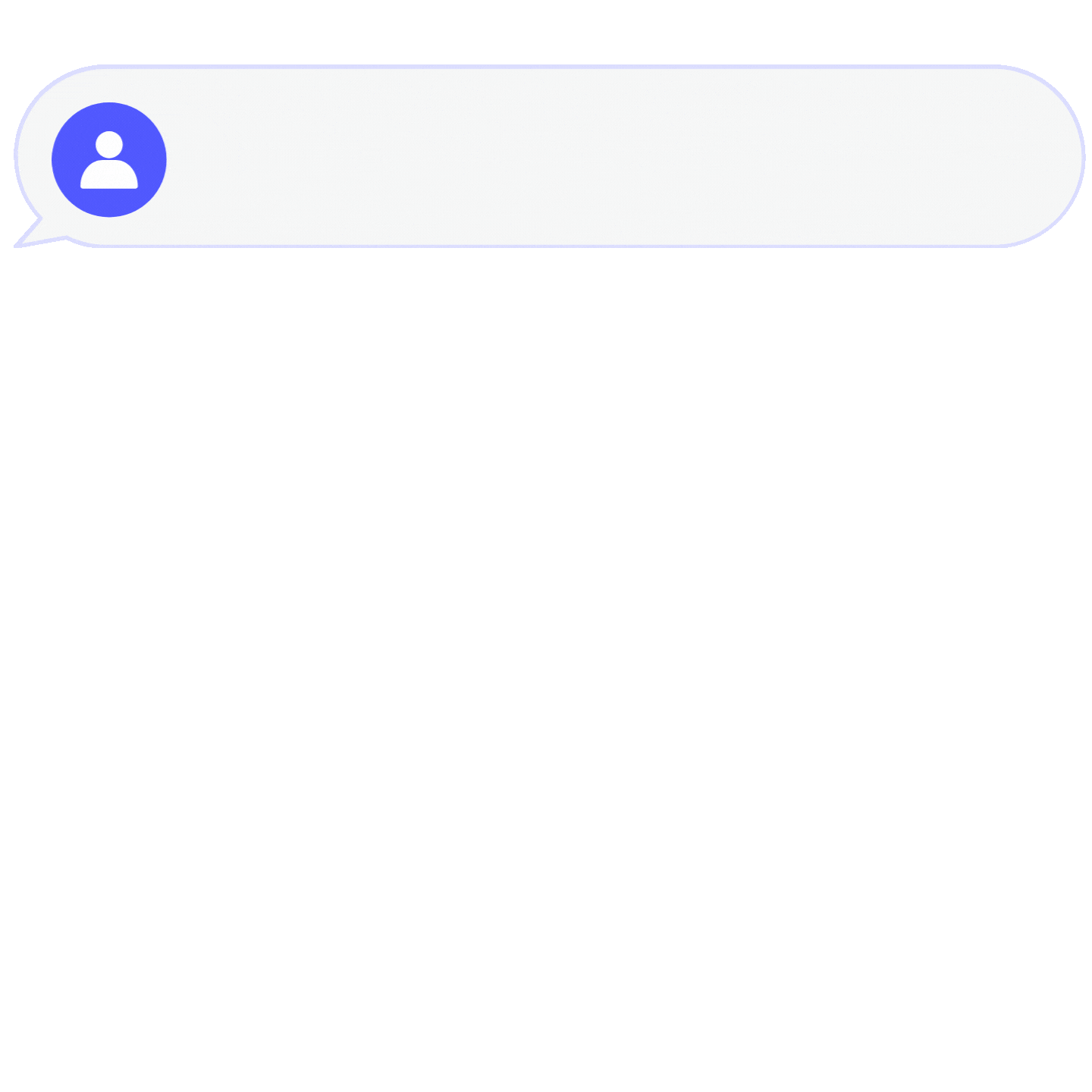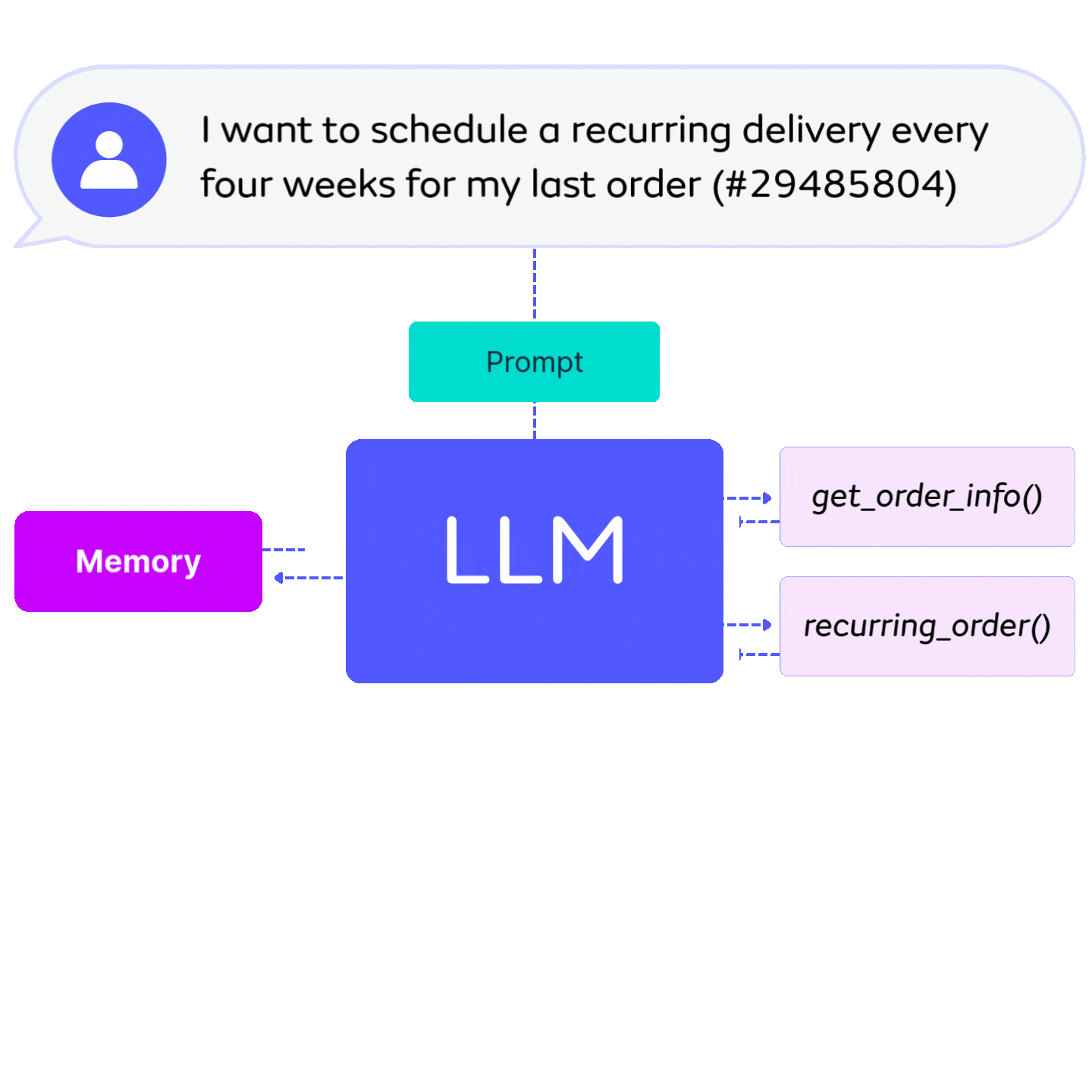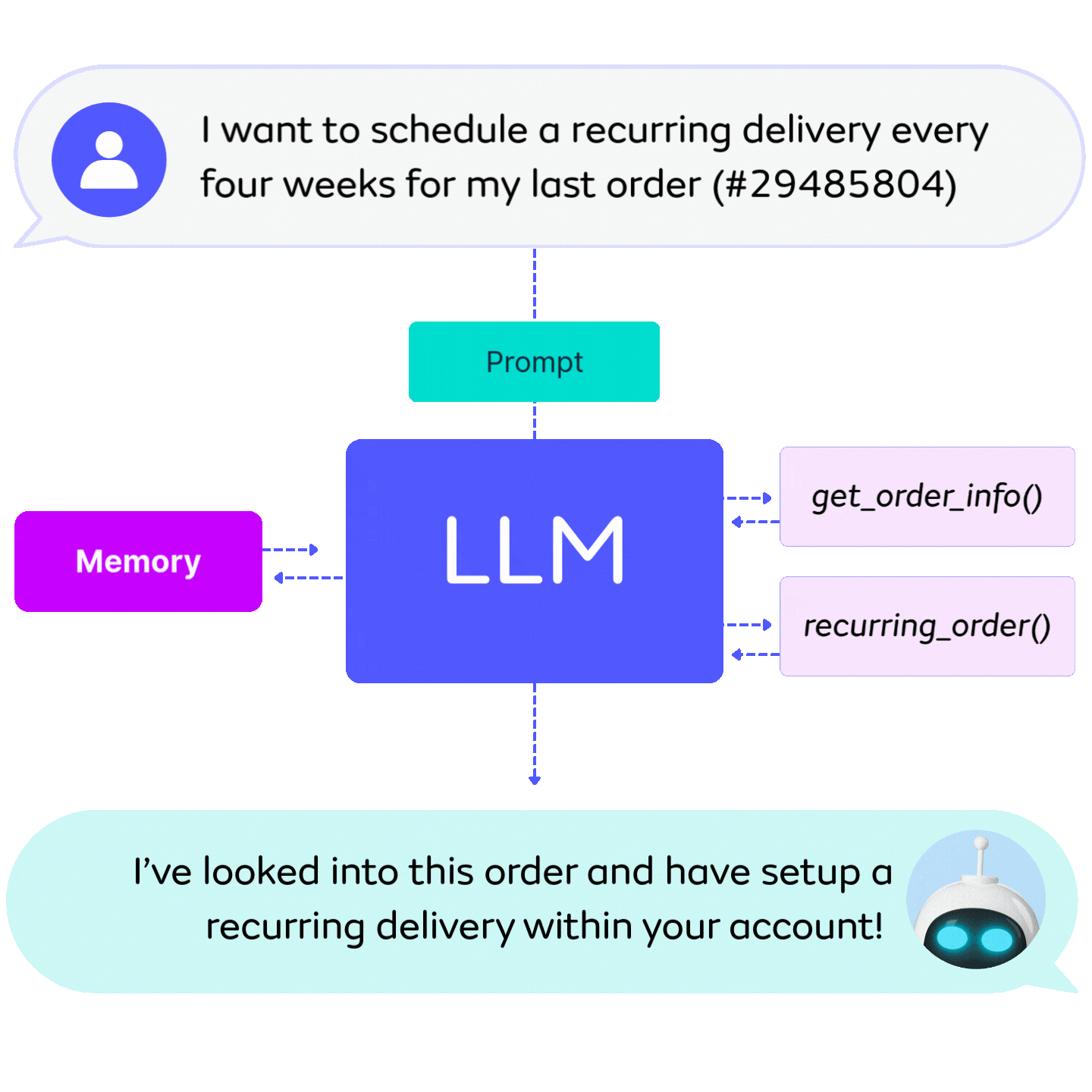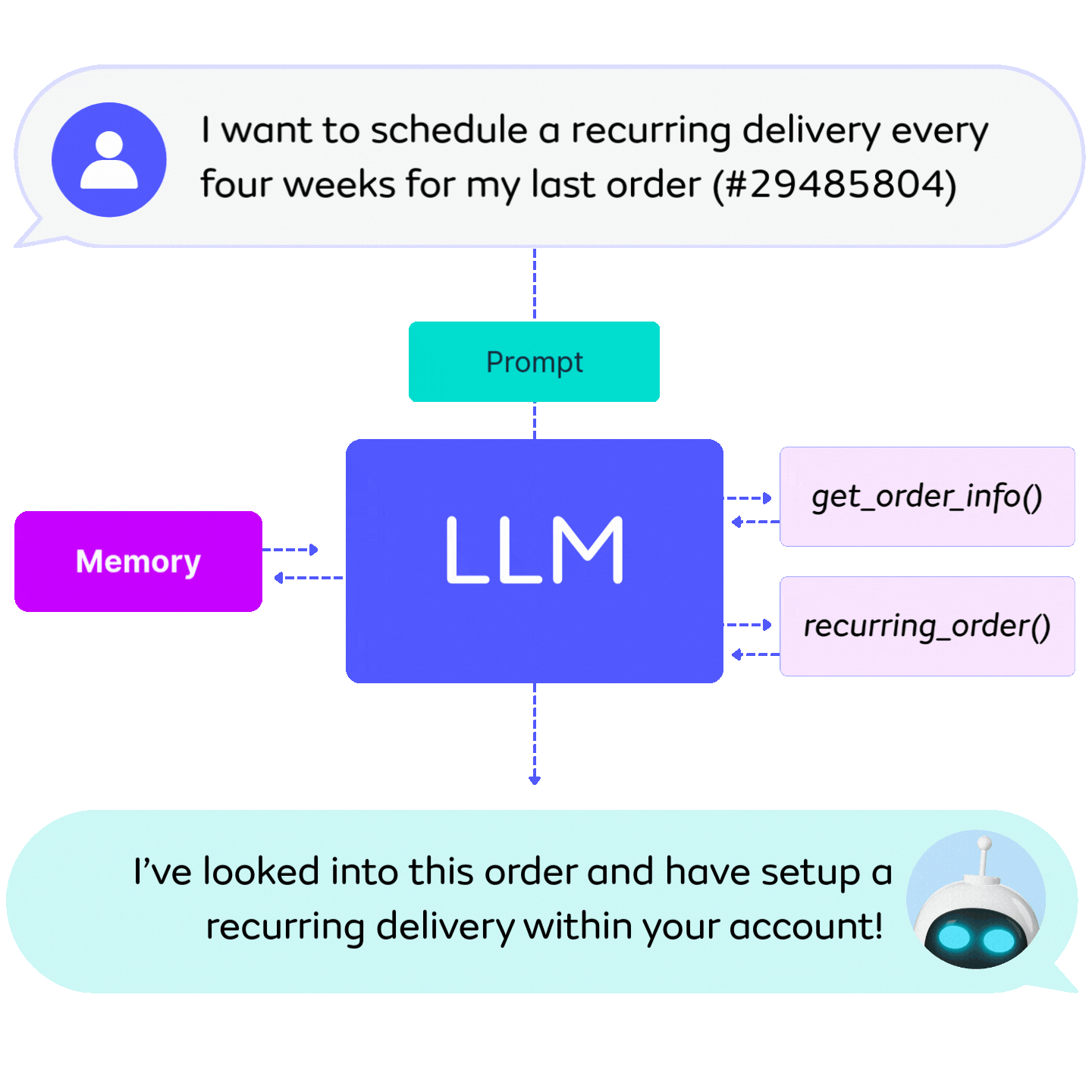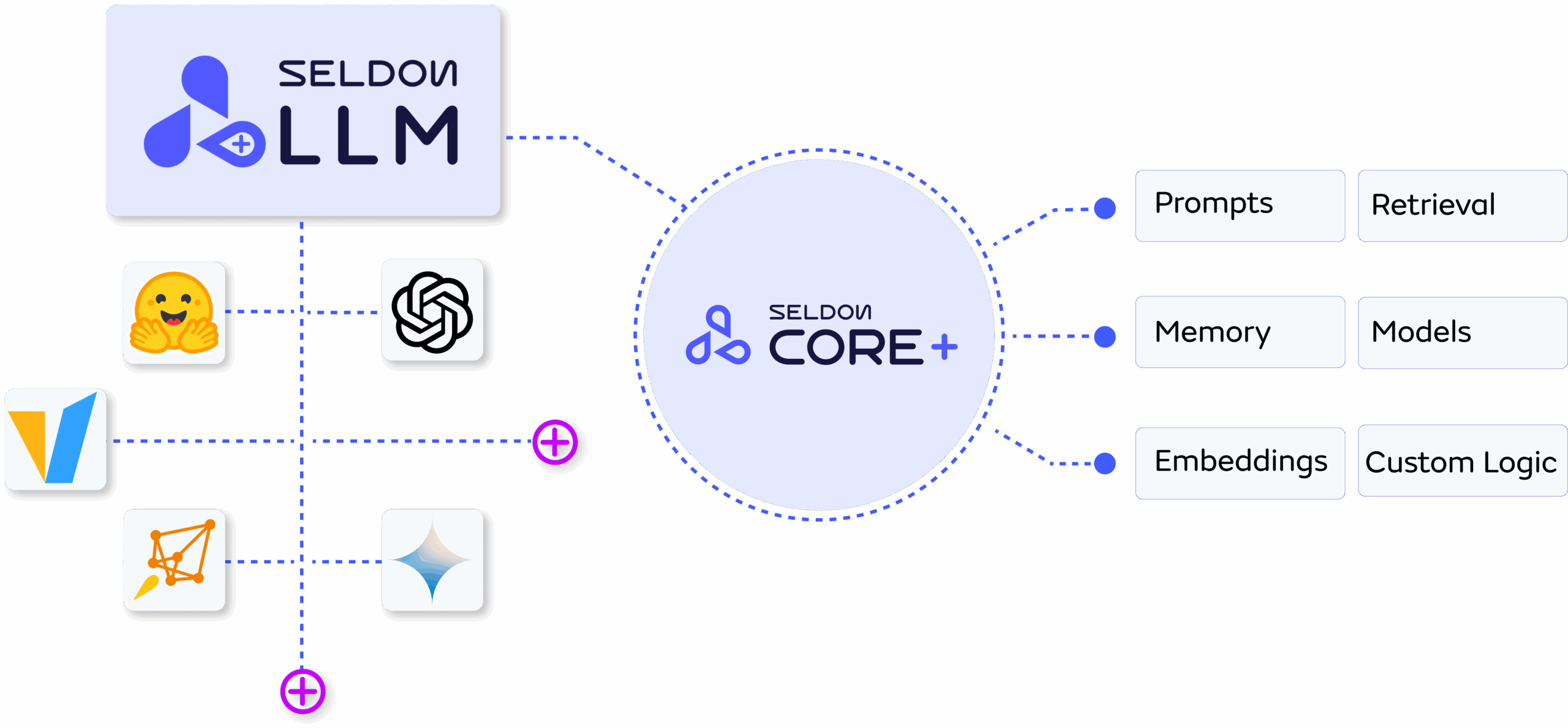




Deploy any LLM, anywhere, including third-party hosted LLMs and high-performance self-hosted deployments. With API and Local deployment, all requests follow Seldon’s Open Inference Protocol for seamless integration into Core 2 pipelines.
Highlights:
Broad LLM support: OpenAI, Gemini, open-source, or custom models.
API runtime: Directly call hosted LLMs from leading providers.
Local runtime: Deploy with DeepSpeed, vLLM, or Hugging Face backends on your own infra.
Optimized performance: LLM-specific serving enhancements to maximize efficiency.
Pipeline-ready: Plug-and-play within Seldon Core 2 workflows.