Machine learning algorithms learn to make predictions or decisions by learning, from historical data, a model of the underlying process connecting inputs (a.k.a. features) and outputs (a.k.a. labels). If this process underlying the data remains unchanged throughout a model’s lifetime then its performance is likely to remain stable over time. However, if the process changes somehow, performance can suffer and the model may no longer remain suitable for deployment.
Data scientists refer to such changes as “drift” and without systems in place to detect when drift occurs the resulting performance degradation can go unnoticed and damage can accumulate over time. This can be particularly problematic in high-stakes and safety-critical applications.
To demonstrate the different ways in which drift can occur, consider the problem of training a machine learning algorithm to predict a person’s voting intention — blue party or red party — given indicators of their economic conservatism and social conservatism. In a simple world, those intending to vote for the blue (resp. red) party might appear as a cluster of economically and socially conservative (resp. liberal) individuals as shown in the figure below and a model with the decision boundary shown by the black dotted line may be able to differentiate between such individuals with high accuracy. The high accuracy of the model may make it suitable for deployment as part of some automated decision-making process.
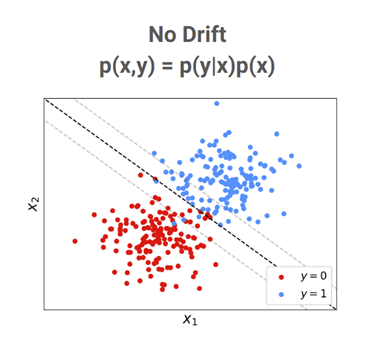
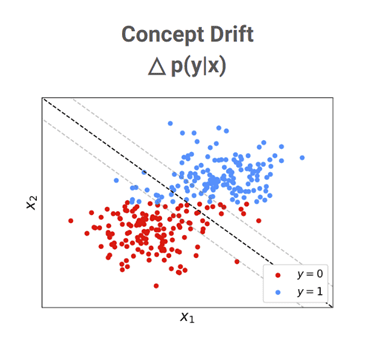
However, suppose that for some reason the relationship between the target (voting intention) and features (economic/social indicators) changes for some reason – perhaps due to a policy change motivating voters to vote purely along social lines (as shown below). The previously suitable decision boundary may no longer be as suitable and the classification accuracy of the model may drop. A change such as this in the relationship between targets and features is referred to as “concept drift”.
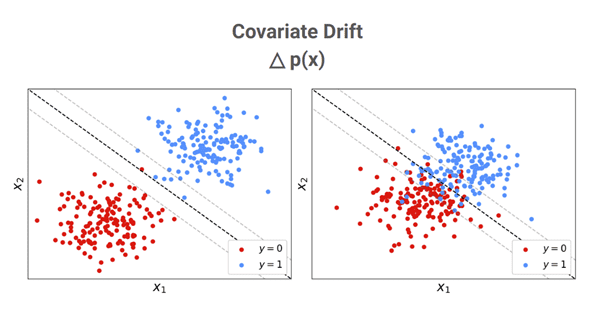
Alternatively, suppose that for some reason society is drawn together such that the clusters of voters are closer together as shown on the right below. Although the relationship between targets and features may have remained the same (e.g. a point on the decision boundary is still a 50/50 probability), the fact that there are more individuals falling into the central region on which the model is uncertain means that the model’s accuracy will be lower. A change such as this in the distribution of features (a.k.a. covariates) is referred to as “covariate drift”.
Note that not all covariate drift is necessarily harmful. If the change was such that society becomes further divided and the clusters are pushed further apart, such as on the left below below, less points may fall into the region on which the model is uncertain and the accuracy may actually improve. Usually, we are interested in detecting drift that degrades model performance, which is referred to as “malicious” drift.
Although this example is relatively low-stakes, machine learning algorithms are increasingly deployed to make decisions in applications such as medical imaging where degradations in model performance resulting from drift may make a model unsuitable or even dangerous to continue using. So, how can we detect drift when it occurs and how can we know when the differences between training and deployment data are due to systemic change or natural fluctuations?
The answer is to apply principles from statistical hypothesis testing. This allows us to detect, with a known probability of a false positive detection, whether two batches of data have different underlying distributions. However, the problem is usually not quite as simple as testing whether a big batch of deployment data has the same underlying distribution as the training data. This is because deployment data usually arrives sequentially and if drift occurs we would like to detect it as quickly as possible in order to limit the accumulated damage.
In this sequential setting we would like to deploy a drift detector with the property that if drift occurs the expected delay between the time at which it occurs and the time at which it is detected is small. However, requiring only this property encourages detectors to make lots of detections and, therefore, we additionally specify how long the algorithm should run for on average before making a false detection.
To learn how we can apply the ideas from statistical hypothesis testing to design algorithms satisfying these two properties, and therefore yield drift detectors capable of alerting us to damaging/dangerous performance degradations, check out the video below:
Those interested in adding drift detection functionality to their own projects are encouraged to check out our source-available Python library Alibi Detect.
