
Multi-model serving (MMS) is cutting-edge functionality with massive potential to enable a team to scale the deployment of models on a small infrastructure footprint by intelligently scheduling models to shared servers.
This is made even more effective by activating “Overcommit” allowing servers to handle more models than can fit in memory. This is done by keeping highly utilized models in memory and pushing other ones to disk using a least-recently-used cache mechanism.
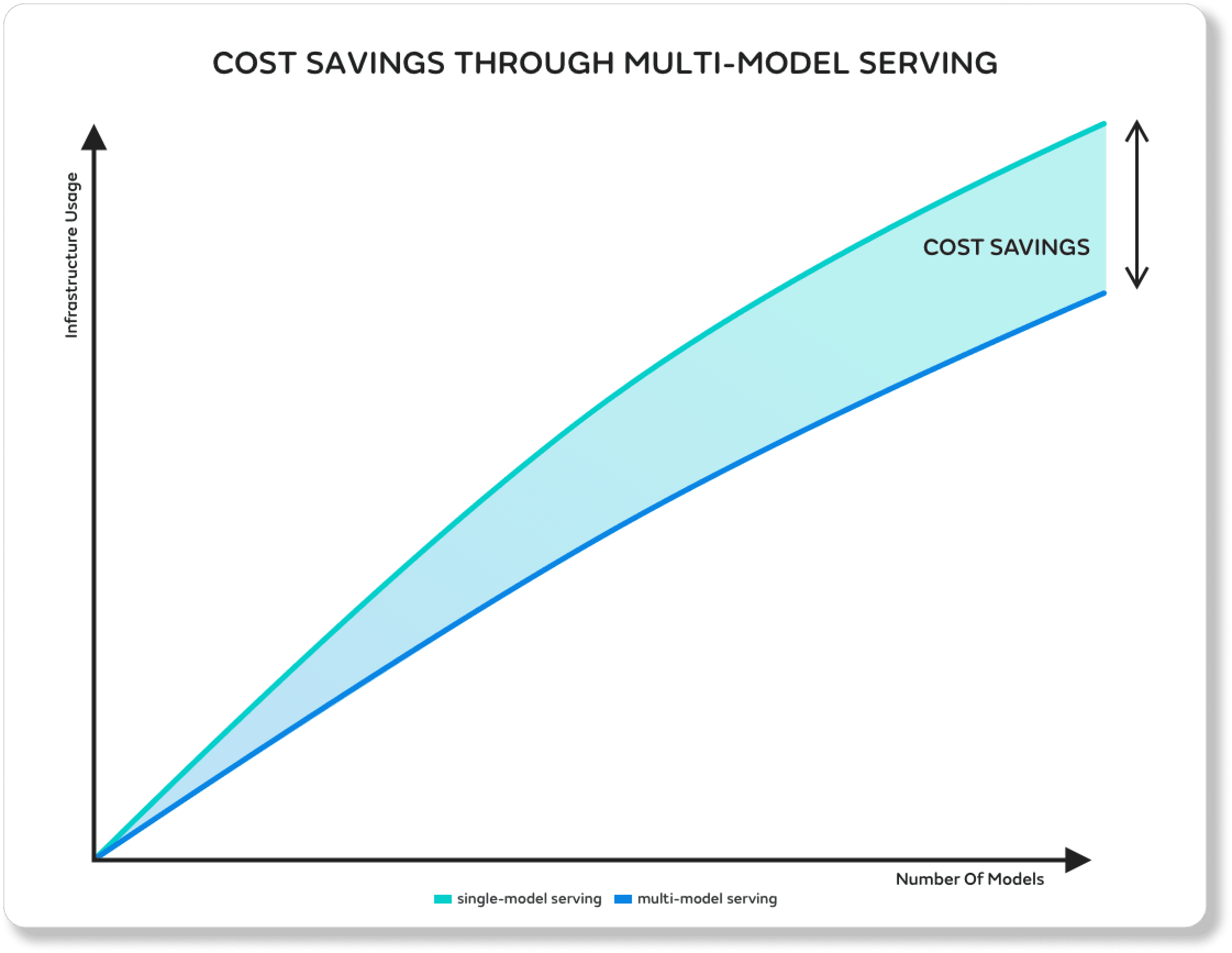
Substantial cost & energy savings through Multi-Model Serving
Multi-Model Serving tackles these growing organizational pain-points when reaching scale. This is a major milestone for the MLOps ecosystem and it has the capability to create substantial cost and energy savings, and with the additional Overcommit Functionality this only further optimizes ML infrastructure.
Production machine learning models can introduce significant overhead when deployed in production. These costs can be attributed to multiple factors, including infrastructure overheads, allocation of specialized resources (high CPU / GPU / memory), etc.
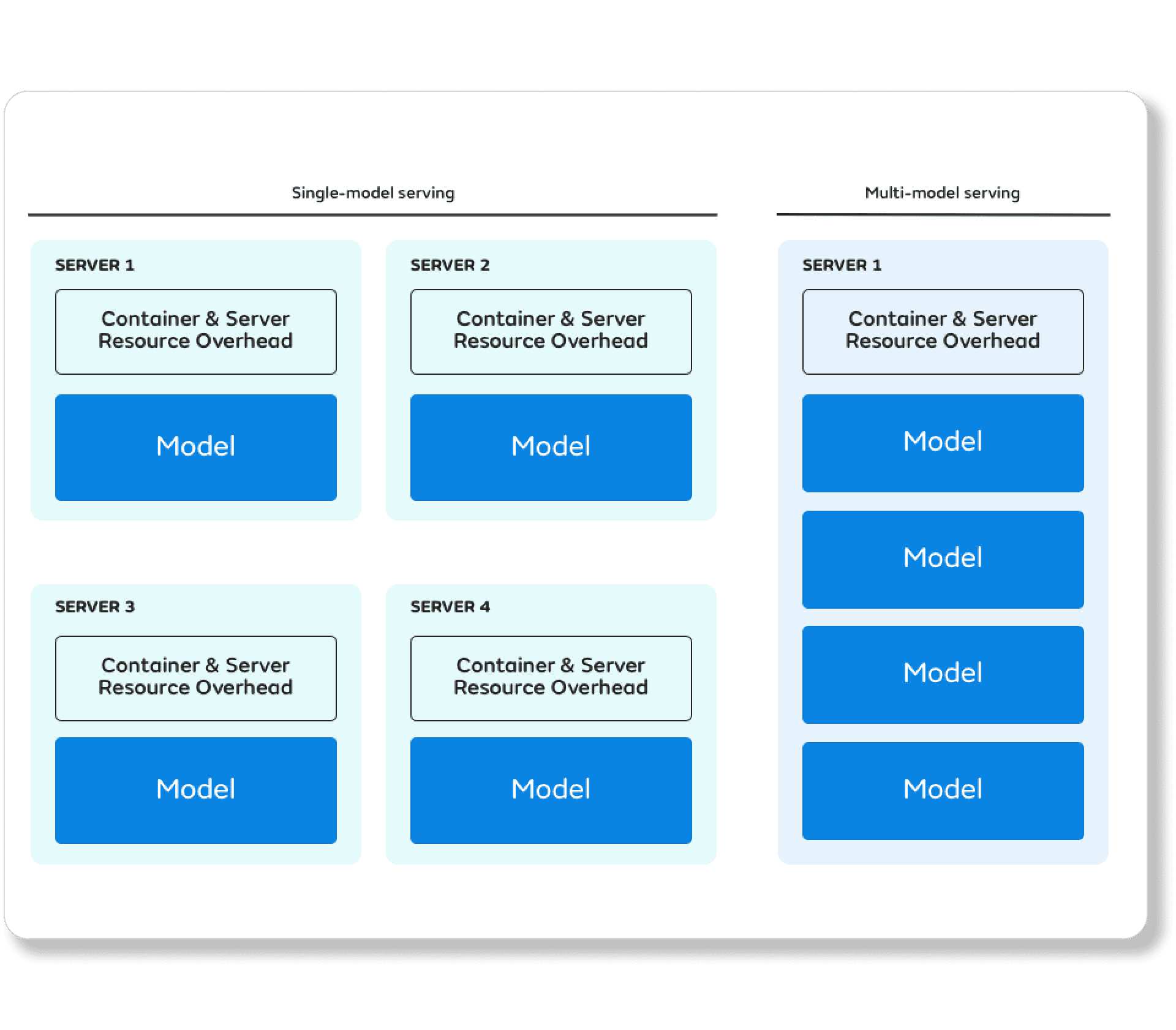
For serving ML models in production, a standard pattern is to package up the ML model inside a container image which then gets deployed and managed by a service orchestration framework (e.g. Kubernetes). While this pattern works well for organizations deploying a couple of models, it does not scale well as there is a one-to-one mapping between a deployed container and an ML model being served.
There are technological limitations that are imposed in the single-model-serving scenario. For example, there is a current Kubernetes limitation on the number of pods per node, which is 110 pods per node. To deploy 20,000 single pod ML models we would need 200 nodes. The smallest node in Google Cloud is e2-micro (1 GB memory) and therefore the total system would require at least 200 GB memory. In fact, the memory requirement is likely to be far greater as it is not possible to have hundreds of model inference server pods on a small node.
With multi-model serving, however, the memory footprint of the system is expected to be one order of magnitude less by design, as resources are shared at the model level. Multi-model serving has additional benefits, too: it allows for better CPU/GPU sharing and it does not suffer from the issue of cold start, where we have to download the container image before starting each ML model to deploy. This can take in the order of tens of minutes. Multi-model serving also reduces the risk of allocating new cloud resources (e.g. GPU) on-demand as model inference servers are long-lived by design.
Single-model-serving, where each model runs in a different container, will result in extra overhead added for each of these containers. The overhead reduction by implementing multi-model serving can have substantial cost savings, especially given how often the environments of machine learning containers can reserve large amounts of memory, numerous CPUs and in some cases expensive GPU / TPU processors.
Infrastructure optimization through Overcommit Functionality
It is usually hard to predict inference usage patterns and therefore provision the right infrastructure in advance. When dealing with MLOps at growing scale, it becomes an even larger challenge when it’s necessary to operationalize thousands of machine learning models. This forces a setup where resources are over-provisioned, which unnecessarily increases the size and the cost of the infrastructure. Instead, by design, Seldon Deploy Advanced scales resources intelligently according to demand even when models have heterogeneous compute demand.
While Multi-Model Serving and Autoscaling help organizations manage infrastructure according to demand, in many cases demand patterns allow for further optimization such as “Overcommit” of resources. In other words, ML systems could register more models than can traditionally be served with the provisioned infrastructure. However, this assumes inference traffic patterns that are complementary in nature, such as different ML models for weekends and weekdays. In these cases we can provision the infrastructure to accommodate one set of models and swap them as required. This is particularly important in resource-constrained environments, such as edge device ML deployments.
With Overcommit, we keep a cache of active models and evict models that are not recently used to warm storage. In the case of an inference request being invoked on an evicted model, the system should be able to activate it to serve the incoming inference request. Given that the evicted model lives in warm storage, loading it back is relatively fast and typically imperceptible to end users.
In using both Multi-Model Serving and Overcommit capabilities together, organizations can have substantial savings in costs of infrastructure resources which could therefore lead to reductions in energy consumption as well.




