
Production machine learning deployment is increasingly multi-faceted. Mission-critical systems often demand redundancy, high throughput or low latency, all of which can mean deploying a model multiple times across many pieces of hardware. A traditional machine learning container-based usage count does not map well to the number of inference services being run. It also creates a disincentive to introduce the aforementioned kinds of service level objectives.
To address this, Seldon has adopted a model-based way of measuring how we enable customers to understand metrics about their production ML models. In order to understand how Seldon’s model usage count works, it’s helpful to first distinguish between containers and models. Let’s have a look at how machine learning containers and models compare to each other, and how they are used in our enterprise products, Seldon Deploy and Seldon Deploy Advanced.
What is a machine learning model?
ML models are algorithms that are used to analyze and make predictions or decisions based on data inputs. They are trained on a dataset, which means that they are taught to find particular patterns or outputs depending on the task. An ML model takes that data and uses it to make predictions or classifications on new data.
A common use case is a type of supervised learning: image classification. With image classification, a set of target objects is defined. Then, a model is trained to recognize them using labeled example photos. This is similar to assigning a name to a face when you tag someone on social media.
What is a machine learning container?
A container is a lightweight, readily distributable package of software. It contains everything needed to run an application, including code, software libraries and settings. A container differs from a machine learning model in that it doesn’t contain an operating system. Instead, it shares the OS kernel with other containers or applications that are running, which improves efficiency.
We get the definition of a container from Kubernetes and Docker. Kubernetes is a dependency for running version 1 of Seldon Core, Seldon Deploy and Seldon Deploy Advanced. With open-source platform Kubernetes, you can orchestrate and manage containers and containerized applications.
What are the benefits of using containers in Machine Learning?
Packaging models into machine learning containers can help to standardize them or make them more portable so that you get the same behavior wherever you run it. Separate project environments make it easy to test-run new packages, modules, and framework versions. This enables ML teams to not have to worry about breaking an entire system, or needing to install each tool on a local host.
How do containers and ML models relate to each other?
When deploying ML models, containers can be used to group the model, along with its dependencies and libraries, into a single, self-contained package. Seldon makes it easy to deploy the model on different environments without worrying about compatibility issues.
In production environments, containers enable the scaling, monitoring, and orchestration of the model. Using Seldon software, customers can automatically scale the number of replicas of a containerized model based on the load. In addition, they can automatically roll out updates to the model without disrupting its service.
How does version 1 of Seldon Core treat containers vs models?
We chose to build version 1 of Seldon Core and version 1 of Seldon Deploy on top of Kubernetes. This is because it provides a way to deploy, scale, and manage containerized applications in distributed environments.
As we only had the ability to do single-model serving in version 1 of Seldon Core and version 1 of Seldon Deploy, when deploying 1 model, we may use ≥ 1 container. This is dependent on the complexity of the model, experimentation or progressive rollout methods customers use. When we count containers, these also include other components of a deployment. This involves data processing/transformation units that are typically applied to input or outputs using version 1 of Seldon Core.
In Seldon Deploy, we count the total number of models based on the following components:
- the number of ML models deployed using Seldon Core
- canaries and shadows of models
- explainer models
How has Seldon changed how containers vs machine learning models relate to each other?
When using Seldon Core 2, and the introduction of multi-model serving, the way that containers and models relate to each other has changed.
When deploying one model, we may still use ≥ one container. However the total number of containers we use may go down. This is because we are doing more efficient optimization of model deployments. This is especially true when not all models need to be running in production at the same time.
We count the total number of models based on the following components:
- the number of ML models deployed using Seldon Core or Seldon Core v2
- deployed replicas of models
- canary/shadows of models
- outlier models
- drift models
- explainer models
What are some examples of containers?
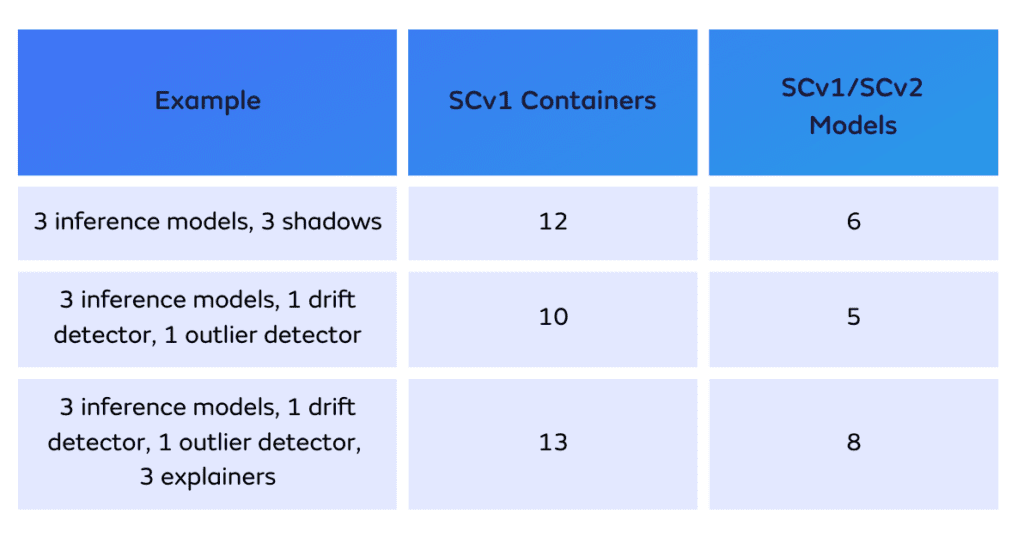
Here are some examples…
Example 1 for Seldon Deploy Advanced
A customer has 3 models in production and runs two A/B tests via shadows on each of the three of them in week 1. That would make 3 models x 2 tests per model = 6 deployed models.
In the previous “container = model” pricing structure, the same example with Seldon Core, would be counted as a total of 12 models. Namely 6 deployed models, each with their respective orchestrator container, which runs on the side.
In week 2, they have the 3 models but don’t run any replicas. Instead, they set up a drift detector for the first model, an outlier detector for the second model and nothing for the third model. So for week 2, usage = 5 deployed models.
In week 3, they have the 3 models, keep their detectors and run A/B tests on the two models with detectors attached. As a result, that’s 3 models, 1 drift detector, 1 outlier detector and 2 models x A/B tests (2*2 + 1 + 1 + 1) = 7 deployed models
In week 4, they have the 3 models, keep their detectors and run A/B tests on the two models with detectors attached and added explainers to all three models. So that’s 3 models, 1 drift detector, 1 outlier detector and 2 models x A/B tests and 3 explainers (2*2 + 1 + 1 +1 +3) = 10 deployed models
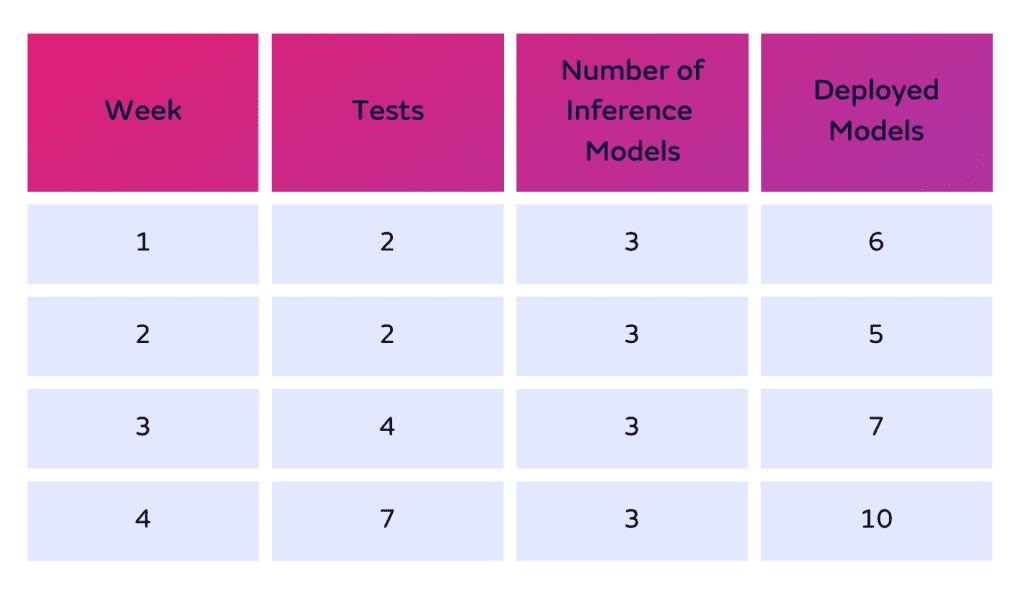
Clients will be charged for the max number of models during the month, which is 10.
Example 2 for Seldon Deploy Advanced
For Seldon Core v2 all components are Models.
If a customer runs a Pipeline that includes a SKLearn model, an outlier detector (MLServer model running Alibi-detect), a drift detector (MLServer model running Alibi-detect) and an explainer (MlServer model running Alibi Explain) = 4 models.
If any of these scale to multiple replicas, these are counted as well. For instance, if we have 10 replicas of the SKLearn model, 4 for outlier detector, 4 for drift detector and 2 for explainer = 20 models.
A second Core v2 Pipeline that uses all the existing models referred to above would mean they still just use 20 models. Pipelines include just references to models. This is a very important point; with Seldon Core v2 runtime, users may have as many pipelines routed through these already deployed models without re-deploying models, i.e without increasing usage count.

Take Control of Complexity With Seldon
With over 10 years of experience deploying and monitoring more than 10 million models across diverse use cases and complexities, Seldon is the trusted solution for real-time machine learning deployment. Designed with flexibility, standardization, observability, and optimized cost at its core, Seldon transforms complexity into a strategic advantage.
Seldon enables businesses to deploy anywhere, integrate seamlessly, and innovate without limits. Simplified workflows and repeatable, scalable processes ensure efficiency across all model types, while real-time monitoring and data-centric oversight provide unparalleled control. With a modular design and dynamic scaling, Seldon helps maximize efficiency and reduce infrastructure waste, empowering businesses to deliver impactful AI solutions tailored to their unique needs.
Talk to our team about machine learning solutions today –>




