
Originally published September 2021 | Updated December 2024
According to Forrester, over 25% of global data and analytics employees report annual losses exceeding $5 million due to poor data quality, with 7% estimating losses of $25 million or more. This number is staggering and considering machine learning optimization (MLOps) can significantly reduce these losses by ensuring data quality, it’s no wonder it’s becoming a necessity across industries.
MLOps, when implemented effectively, is a powerful tool that continues to transform every industry with it’s ability to leverage data and automate decision-making. Building a successful machine learning model is a critical step that requires thoughtful planning and execution to ensure your data is utilized effectively.
While there are thousands of model types to explore (a topic for another blog), let’s start with the fundamentals, with focus on six essential steps to develop a machine learning model to gain a better understanding of how the process works.
What is MLOps
First thing’s first, why are MLOps and AI all anyone is talking about, and is it actually necessary for me to understand?
MLOps is summarized as a set of practices that create an assembly line for building and running machine learning models. At its core, it involves automating tasks to foster productive collaboration among data scientists, engineers, and even non-technical stakeholders, ultimately enhancing models and their outputs.
Seldon’s focus on the deployment of models, with our real-time machine learning framework with enhanced observability. However, the development of your models before deployment is arguably one of the most significant parts of the MLOps process, as when it’s done right, can help save time and resources in the long run.
Using a tool like Seldon enables faster model deployment through advanced experimentation features and flexible, agnostic approach that seamlessly integrates with your existing legacy stack and adapts to future requirements. Choosing a tool with modular development enables teams to focus on functionality that helps reduce financial costs typically associated with big-box providers and minimizes time costs through modular, reusable development.
Any business that collects and uses data needs machine learning. It’s a set of automations that extends across all industries, addressing diverse use cases such as proactively monitoring financial transactions for fraud in banking or advancing diagnostic tools in healthcare. However, adopting new technologies often comes with significant challenges, including steep financial and time costs, regulatory compliance, and increased strain on in-house data science or ML engineering teams.
By fostering a company-wide understanding of machine learning processes, such as the “what” and “how” of different model types—businesses can build a stronger foundation for MLOps, driving both confidence and investment in these transformative solutions.
Six steps to build a machine learning model
Although different types of machine learning will have different approaches to training a model, there are basic steps that are utilized by most models. Algorithms need large amounts of high quality data to train a model that works well for a given use-case. Many of the steps deal with the preparation of this data, so that the model can be as effective as possible. The whole project needs to be properly planned and managed from the beginning, so that a model fits the organization’s specific requirements. So the initial step deals with understanding those requirements as they pertain to the organization as a whole.
1. Define goals and requirements for your model
Identify the Reason or Need for Machine Learning in Your Organization
A deployed model is only as powerful as the question or questions you are trying to answer, and with machine learning development often being so resource intensive, setting clear objectives from the start will help identify the actual value to the business and any model refinement and management long-term.
We suggest starting with these questions to help ensure the team is on the right track and understand what is needed or missing:
- Owners of the machine learning project
- Problem the project needs to solve, and a definition of project success
- Type of problem the model will need to solve
- Goals of the model to understand return on investment once deployed
- Source of training data and whether it is of sufficient quantity and quality
- Decide if any pre-trained models* can be deployed.
*A pre-trained model is a model that is already created. Reusing an existing model to solve a similar problem helps to reduce waste and streamline model learning through the process of transfer learning, cutting down on your required resources for the project, especially handy with models that require large arrays of labeled training data.
2. Explore the data and choose the type of algorithm
Identify the Type of Model That is Required
The differences depend on the type of task the model needs to perform and the features of the dataset at hand. Initially the data should be explored by a data scientist through the process of exploratory data analysis. This gives the data scientist an initial understanding of the dataset, including its features and components, as well as basic grouping.
The type of machine learning algorithm chosen will be based on an understanding of the core data and problem that needs to be solved. Machine learning models are broadly split into three major types.
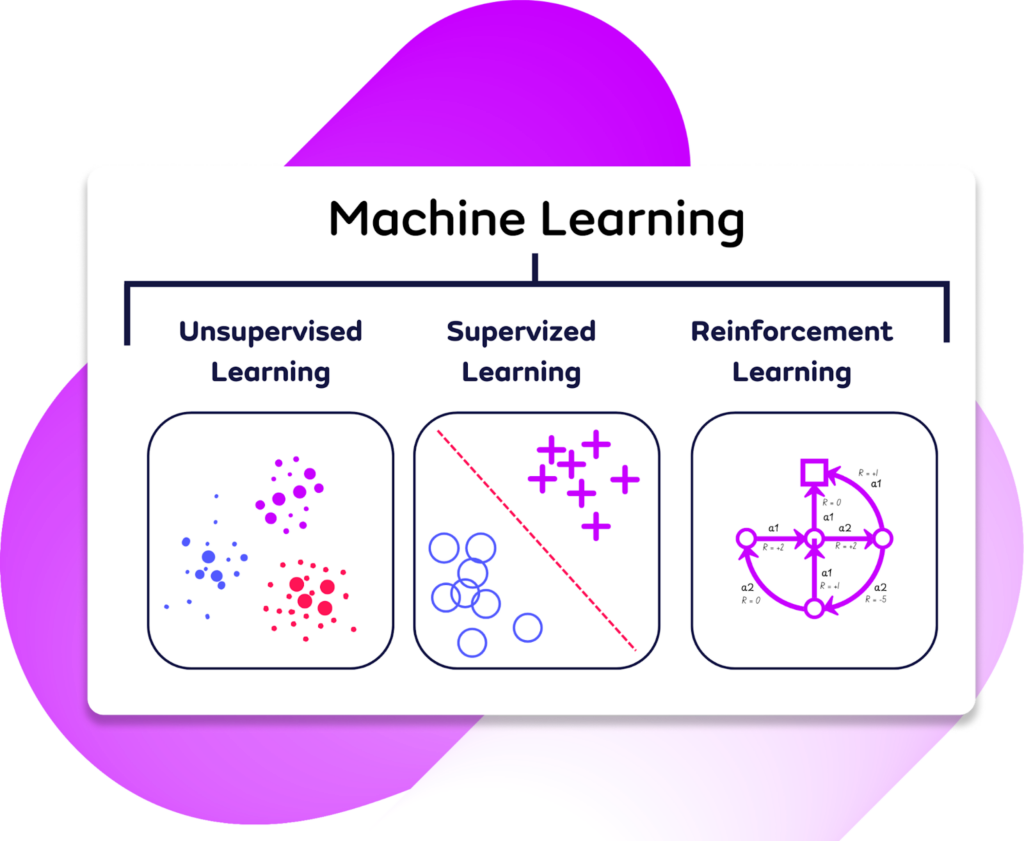
Unsupervised Learning: This approach learns from data without labeled outputs, requiring only input variables. It is designed to uncover hidden insights, patterns, trends, or groupings without direct supervision. Common techniques include clustering (e.g., customer segmentation) and dimensionality reduction (e.g., simplifying complex datasets).
Supervised Learning: Widely used in predictive analytics and decision-making, and relies on labeled datasets to train models which have been prepared by a data scientist. The training dataset will therefore include input and labeled output data for tasks. The model then learns the relationship between input and output data.
Reinforcement Learning: Used a lot for applications that include the likes of any AI development through its use of a trial-and-error feedback loop to optimize actions in dynamic environments. It does this through reward signals that are released whenever a successful action is performed, and the system learns through trial and error. Think driverless cars that have to learn about their environments and what impacts certain decisions that will help it improve from past experiences.
3. Prepare and clean the dataset
Ensure Accuracy for Better Trust and Insight
Machine learning models typically require large volumes of high-quality training data to ensure accuracy. These models learn the relationships between input and output data from the training dataset, and the composition of these datasets varies based on the type of machine learning being performed.
As an example, supervised machine learning models are trained on labeled datasets, which include both input variables and their corresponding output labels. Preparing and labeling this data is usually the responsibility of a data scientist and can be a labor-intensive process. In contrast, unsupervised machine learning models do not require labeled data, relying solely on input variables or features in the training dataset.
In both cases, the quality of the data plays a critical role in determining the model’s overall effectiveness. Poor-quality training data can lead to ineffective models once deployed. To mitigate this, data should be thoroughly checked and cleaned to ensure standardization, identify missing data, and detect outliers.
4. Split the prepared dataset and perform cross validation
Exploring Unseen Data to Validate Model Effectiveness
The real-world effectiveness of a machine learning model depends on its ability to generalize. While data isn’t traditionally talked about in generalizations, this concept is about the model’s ability to apply the logic it learned from training data to new and unseen data.
Models are often at risk of overfitting, where the algorithm becomes too closely aligned to the training data. This can result in reduced accuracy or even a complete loss of functionality when handling new data in a live environment. To counter this, the dataset is typically split into training and testing subsets. A significant portion (e.g., 80%) is allocated for training, while the remaining portion serves as testing data. The model is trained using the training dataset and then evaluated on the testing dataset, which acts as new, unseen data. This process helps assess the model’s accuracy and its ability to generalize.
This process is also called cross validation in machine learning. These are methods that stimulate how a model will perform in real-world scenarios, ensuring the model doesn’t merely memorize the training data but can generalize effectively. These methods are categorized into exhaustive and non-exhaustive approaches:
Exhaustive Techniques: These methods test all possible combinations and iterations of training and testing datasets. While exhaustive techniques provide the most detailed insights into the dataset and model performance, they are time-consuming and resource-intensive. They’re best suited for situations where accuracy is critical and computational resources are not a constraint.
Non-exhaustive Techniques: these involve creating randomized partitions of training and testing subsets. These methods are much faster and require fewer resources, making them a practical choice for scenarios where quicker evaluations are needed without compromising too much on accuracy.
5. Perform machine learning optimization
Improve Model Accuracy and Efficiency
Model optimization is an integral part of achieving accuracy in a live environment when building a machine learning model. The aim is to tweak model configuration to improve accuracy and efficiency. Models can also be optimized to fit specific goals, tasks, or use cases. Machine learning models will have a degree of error, and optimization is the process of lowering this degree.
The process of machine learning optimization involves the assessment and reconfiguration of model hyperparameters, which are model configurations set by the data scientist. Hyperparameters aren’t learned or developed by the model through machine learning. Instead, these are configurations chosen and set by the designer of the model. Examples of hyperparameters include the structure of the model, the learning rate, or the number of clusters a model should categorize data into. The model will perform its tasks more effectively after optimisation of the hyperparameters.
Historically, the process of hyperparameter optimization were performed through trial and error. This was extremely time consuming and resource intensive. Now, optimization algorithms are used to rapidly assess hyperparameter configuration to identify the most effective settings. Examples include bayesian optimisation, which takes a sequential approach to hyperparameter analysis. It takes into account hyperparameter’s effect on the target functions, so focuses on optimizing the configuration to bring the most benefit.
6. Deploy Your Optimized Model
The last step in building a machine learning model is the deployment of the model.
Development and testing an ML model takes place in a local or offline environment utilizing your training and testing datasets.
Deployment of an ML model is when your model moves into a live environment, dealing with new and unseen data, and delivers return on investment to the organization as it is performing the task it is trained to do with live data.
More and more organizations are leveraging containerization as a tool for machine learning deployment. Containers are a popular environment for deploying machine learning models as the approach makes updating or deploying different parts of the model more straightforward. As well as providing a consistent environment for a model to function, containers are also intrinsically scalable. Open-source platforms like Kubernetes manage and orchestrate containers, and automate elements of container management like scheduling and scaling.





