The Kubernetes MLOps ecosystem continues to evolve at breakneck speed, however it is critical to ensure the foundational features and functionality of the underlying infrastructure is kept up to date with key changes in the ecosystem. This release of Seldon Core v1.11.0 focuses on a variety of quality of life improvements to build upon the key foundational features of the infrastructure, servers and documentation resources.
This release of Seldon Core includes deeper support on Kubernetes Status Updates, introduces Adaptive Batching in MLServer, upgrades to the latest Triton Server, extends support to Kubernetes 1.21, adds options for rbac leadership election, and introduces a set of MLFlow model deployment examples using Seldon Core directly, as well as leveraging the Tempo SDK. For a complete overview of all the changes introduced you can view the release changelog.
Kubernetes Status Updates
In this release of Seldon Core we have updated the status section of the SeldonDeployment resource to include the standard Kubernetes conditions section. This will allow users of Seldon Core to get more insight into the deployment stage for their inference graph. Users will now see a section as below:
status: address: url: http://seldon-model-example.seldon.svc.cluster.local:8000/api/v1.0/predictions conditions: - lastTransitionTime: "2021-09-13T09:21:41Z" message: Deployment does not have minimum availability. reason: MinimumReplicasUnavailable status: "False" type: DeploymentsReady - lastTransitionTime: "2021-09-13T09:21:41Z" reason: No HPAs defined status: "True" type: HpasReady - lastTransitionTime: "2021-09-13T09:21:41Z" reason: No KEDA resources defined status: "True" type: KedaReady - lastTransitionTime: "2021-09-13T09:21:41Z" reason: No PDBs defined status: "True" type: PdbsReady - lastTransitionTime: "2021-09-13T09:21:41Z" message: Deployment does not have minimum availability. reason: MinimumReplicasUnavailable status: "False" type: Ready - lastTransitionTime: "2021-09-13T09:21:41Z" reason: Not all services created status: "False" type: ServicesReady deploymentStatus: seldon-model-example-0-classifier: replicas: 1 replicas: 1 state: Creating |
The status conditions are available for dependent
Services, PDBs, KEDA, HPAs, Deployments and overall Ready condition.
With these added sections one can now use the ability to wait for the ready status of a SeldonDeployment with the kubectl command. An example would be:
kubectl wait --for condition=ready --timeout=300s sdep --all -n seldon seldondeployment.machinelearning.seldon.io/seldon-model condition met |
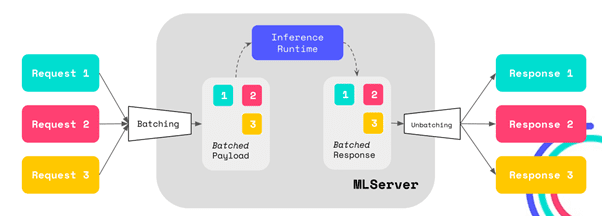
Adaptive Batching in MLServer
As part of our ongoing benchmarking and performance improvements workstreams, we have added adaptive batching capabilities to MLServer that allow for more efficient processing, especially when leveraging hardware-parallel processing via multiple cores or GPUs. Adaptive batching consists of grouping incoming requests into batches that can be processed together, as opposed to one by one. The adaptive batching functionality being added is also configurable to have a variable maximum batch size (i.e. how many requests should we group together at most) and maximum time to wait to reach that size.
You can read more about how to enable adaptive batching in MLServer in this documentation page.
Support for MLflow Model Signatures
As part of our collaboration with the MLflow team, MLServer should now be able to read (and understand) the model signature saved with your MLflow artifact. Based on it, it will now be able to infer the V2-compliant metadata for your model, which can be consulted through the metadata endpoint of the V2 protocol. On most cases, MLServer will also be able to translate your model’s input signatures into the right content types so that request payloads get decoded on-the-fly as the right Python type (e.g. Pandas DataFrame, Numpy arrays, base64-encoded strings, etc.).
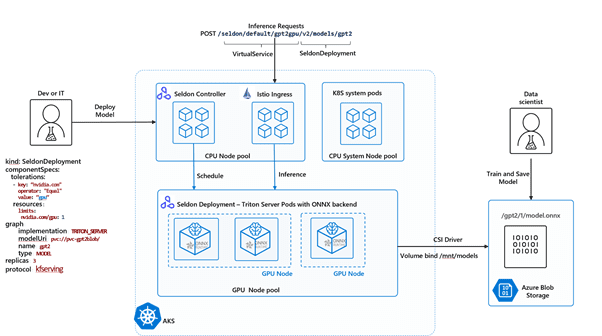
Updating to Triton Server v21.08
We have seen a greater adoption of Seldon Core for users that want to deploy their models using the highly optimized NVIDIA Triton server. In this release of Seldon Core we update the supported version of NVIDIA Triton to the latest version at this time of writing which is v21.08. We have several resources that showcase the power of NVIDIA Triton with Seldon Core, including our recent collaboration with Microsoft where we showcase in this blog post how to deploy a GPT-2 model optimized for ONNX Runtime in Azure Kubernetes Service. We have also done some work to extend this and a hands on tutorial that showcases how to perform the same deployment in a Kubernetes cluster but using the Tempo SDK instead.
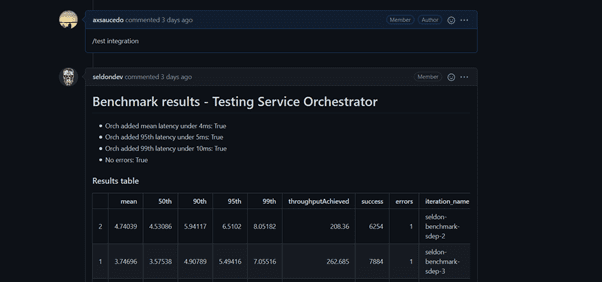
Extended Support to Kubernetes 1.21
As part of our ongoing workstream to ensure robustness on cloud native infrastructure, we ensure that the latest versions of Kubernetes are not only supported but also thoroughly tested across all the broad range of features that Seldon Core offers. For this we have reinforced our continuous integration suite to run on the latest Kubernetes which at the time of writing is 1.21.0. Our integration tests run in a Kubernetes cluster leveraging Tekton, and test all features and integrations by spinning up a fresh cluster with KIND (Kubernetes in Docker) that allows us to perform reproducible tests that validate end to end flows with any relevant 3rd party infrastructure dependencies and versions. Below is an example of the integration tests that we run for our automated benchmarking which we introduced and described in our 1.10.0 release.
We have also updated the operator and service orchestrator (executor) applications to be based on Go 1.16 utilizing 1.21 Kubernetes libraries.
Configurability for Leadership Election
We now provide customization to set the leadership election ID used when the operator manager starts up. The helm chart has a default value which can be overridden with manager.leaderElectionID. This would allow multiple operators to be run in the same namespace without interfering on startup.
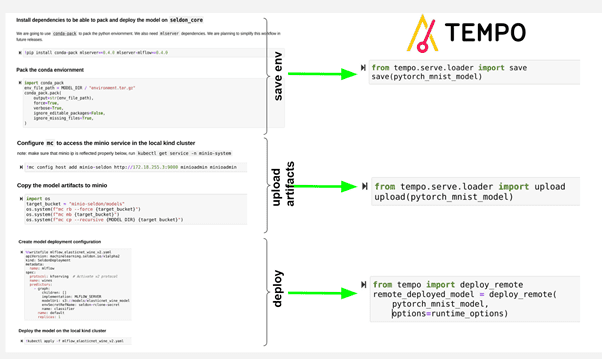
Extended MLFlow Examples
We have added two new end to end examples that show how to leverage MLServer (our V2 Python Server) to deploy MLFlow models that can benefit from the features and integrations with the framework covered in our previous release. The first example covers how to deploy MLFlow models directly with Seldon Core through applying the YAML directly. The second example shows how you can leverage our new Seldon Core SDK called Tempo which abstracts the interactions with Kubernetes to make the workflows seamless for data scientists.
Both examples are equally relevant, but focused on the platform/MLE team and data science team “personas” respectively. Below the image shows both examples side by side, as well as the steps that can be performed directly against the Kubernetes cluster, or abstracting these using the Tempo SDK.
Get Involved
The 1.11.0 release notes provide the full list of changes. We encourage users to get involved with the community and help provide further enhancements to Seldon Core. Join our Slack channel and come along to our community calls.