Written by Seldon and Anyscale‘s Bill Chambers
Serving models at scale is only part of the battle. In general, you’re going to have to be able to explain predictions as well. We, at Seldon, know the challenges of working with a number of models and serving them in production but our users constantly struggled with making sure that they understood why those predictions were made.

Join us to hear about Ray, real-world use cases, and amazing keynotes!
For this reason, we started the Alibi library. Alibi is an open-source Python library for ML model inspection and interpretation. It allows users to run popular model explainability algorithms such as Kernel SHAP on their data. However, while we have a number of algorithms, it’s often that users seek better performance and scaling. In search of a solution, we stumbled upon Ray, an open-source framework that provides a simple, universal API for building distributed applications. To test Ray’s ability to scale, we decided to test scaling the Kernel SHAP algorithm on top of Ray.
A preview of the results can be seen below. In short, we were able to achieve linear scaling of the Algorithm by leveraging Ray Core. You can see the results across 32 virtual cores below. Check out the GitHub repository for the full code and results as well.
Let’s dive a bit deeper into Alibi, Kernel SHAPhap, how we approached distributing Kernel SHAPhap, and the results we achieved.
What is Alibi?
Alibi is a Python package designed to help explain the predictions of machine learning models and gauge the confidence of predictions. The focus of the library is to support the widest range of models using black-box methods where possible. Alibi currently ships with 8 different algorithms for model explanations including popular algorithms like anchors, counterfactuals, integrated gradients, Kernel SHAP, and Tree SHAP.
Recently, we worked on a project where we needed to be able to scale our explainability computations over a large number of CPUs. This is necessary since black-box methods model the prediction function post-hoc and are slow, making the task of explaining large numbers of instances prohibitively expensive on a single CPU.
We figured we could explore utilizing a larger machine, but many of our customers operate in distributed environments and therefore need consistently scalable solutions – beyond a single machine. In order to scale this, and avoid having to write a new distributed system from scratch, we looked for existing libraries that could do some of the heavy lifting for us. To do so, we selected a popular algorithm called Kernel SHAP.
Kernel SHAP
As mentioned in our documentation, Kernel SHAP provides model-agnostic (black box), human interpretable explanations suitable for regression and classification models applied to tabular data. This method is a member of the additive feature attribution methods class; feature attribution refers to the fact that the change of an outcome to be explained (e.g., a class probability in a classification problem) with respect to a baseline (e.g., average prediction probability for that class in the training set) can be attributed in different proportions to the model input features.
A simple illustration of the explanation process is shown in Figure 1. Here we see depicted a model which takes as an input features such as Age, BMI or Sex and outputs a continuous value. We know that the average value of that output in a dataset of interest is 0.1. Using the Kernel SHAP algorithm, we attribute the 0.3 difference to the input features. Because the sum of the attribute values equals output – base rate, this method is additive. We can see for example that the Sex feature contributes negatively to this prediction whereas the remainder of the features have a positive contribution. For explaining this particular data point, the Age feature seems to be the most important. See our examples on how to perform explanations with this algorithm and visualise the results using the shap library visualisations here, here and here.

Figure 1: Cartoon illustration of black-box explanation models with Kernel SHAP Image Credit: Scott Lundberg
The challenge: Global Explanations with Kernel SHAP
As explained above, Kernel SHAP is a method for explaining black box models on tabular data. However, computing these explanations is very expensive, so explaining many model predictions to obtain a global view of the model behaviour on a single CPU or machine is challenging since it entails making a large number of model prediction calls. However, since the predictions are independent, we can parallelize the computation of the explanation for each prediction, which itself could result in a significant time saving given an efficient distributed computation framework. We explored several different computing frameworks but landed on Ray because of the simple API, Kubernetes support, and Ray’s strong community.
In a few short days, we were able to go from concept to prototype.
Our Solution
There are two architectural variations of the solution that we built. The core architecture is simple, we create a pool of worker processes and then pass some computation function to them that will be parallelized and they subsequently execute the work. However, there are two ways to create this pool. One method uses a pool of Ray Actors, which consume small subsets of the 2560 model predictions to be explained. The other method uses Ray Serve instead of the parallel pool and we submit work to Ray Serve as a batch processing task. The code for both methods are available in the github repository and both had similar performance results.
Single Node Results
Single node
The experiments were run on a compute-optimized dedicated machine in Digital Ocean with 32vCPUs. This explains the performance gains attenuation below.
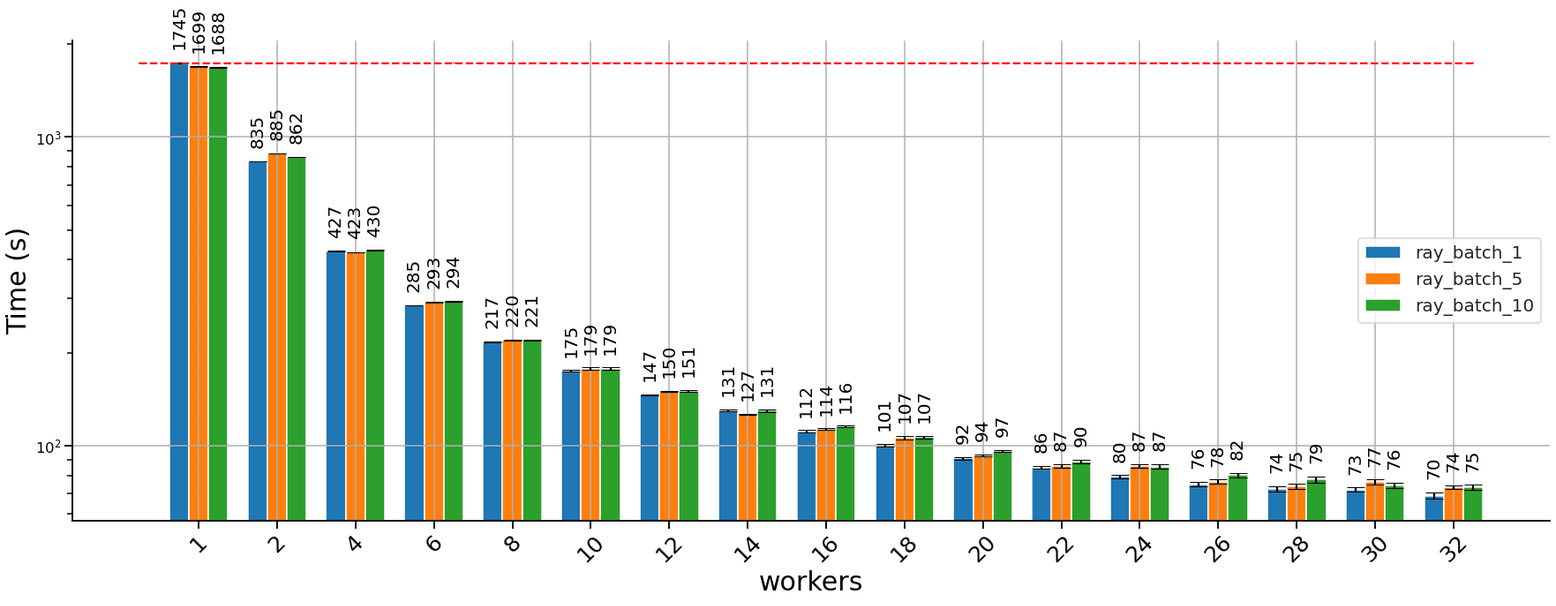
The results obtained running the task using the Ray parallel pool are below:
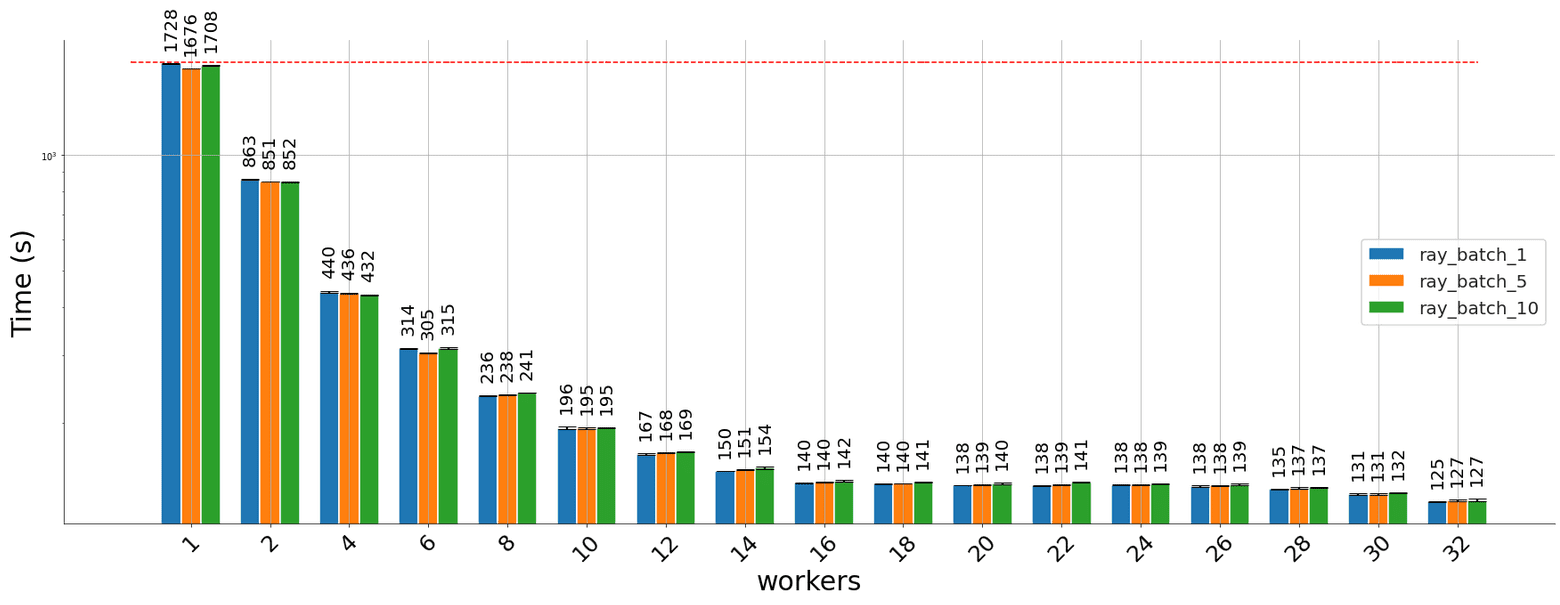
Distributing using Ray serve yields similar results:

Distributed Results
Kubernetes cluster
The experiments were run on a cluster consisting of two compute-optimized dedicated machines in Digital Ocean with 32vCPUs each. This explains the performance gains attenuation below.
The results obtained running the task using the Ray parallel pool over a two-node cluster are shown below:
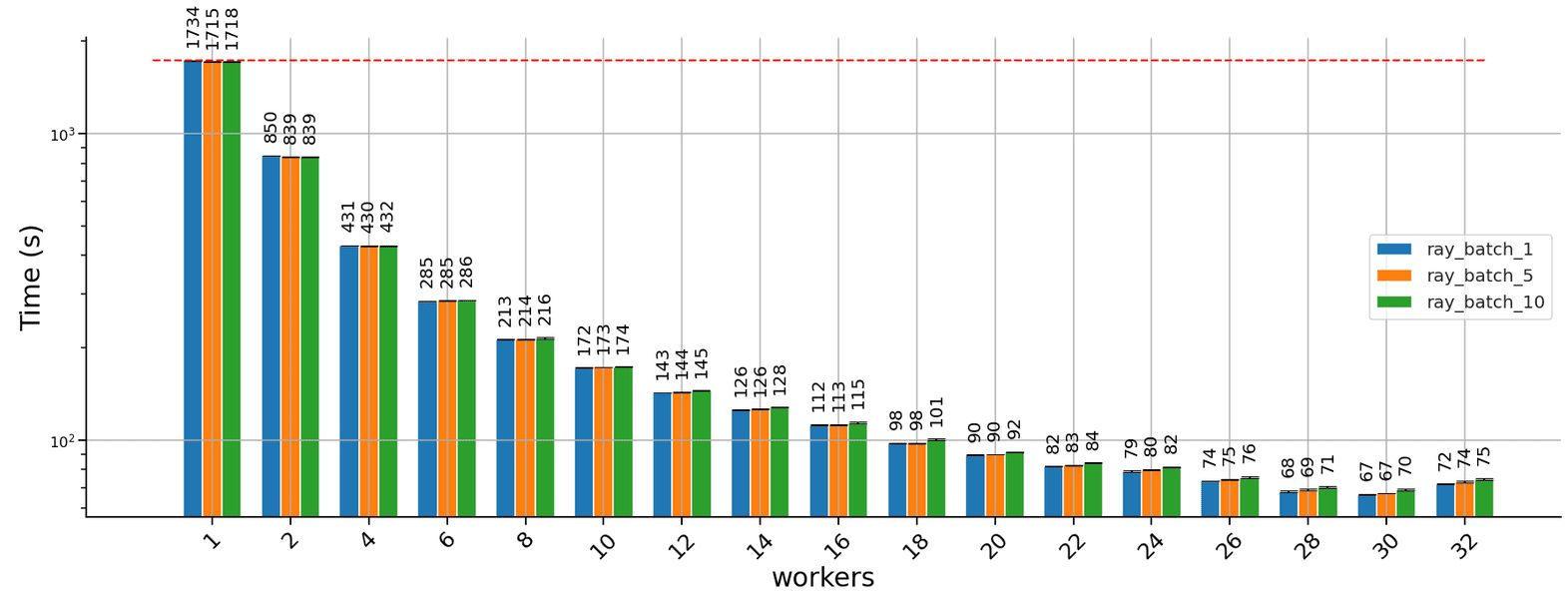
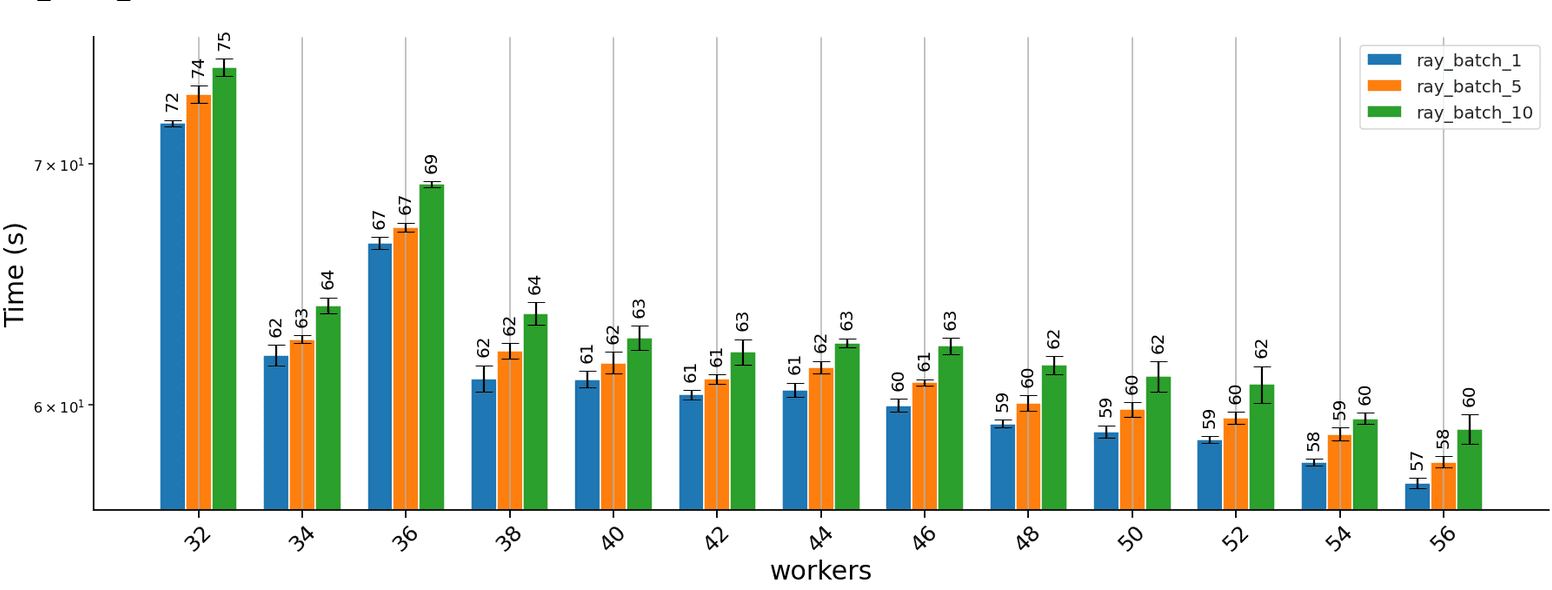
Distributing using Ray serve yields similar results:
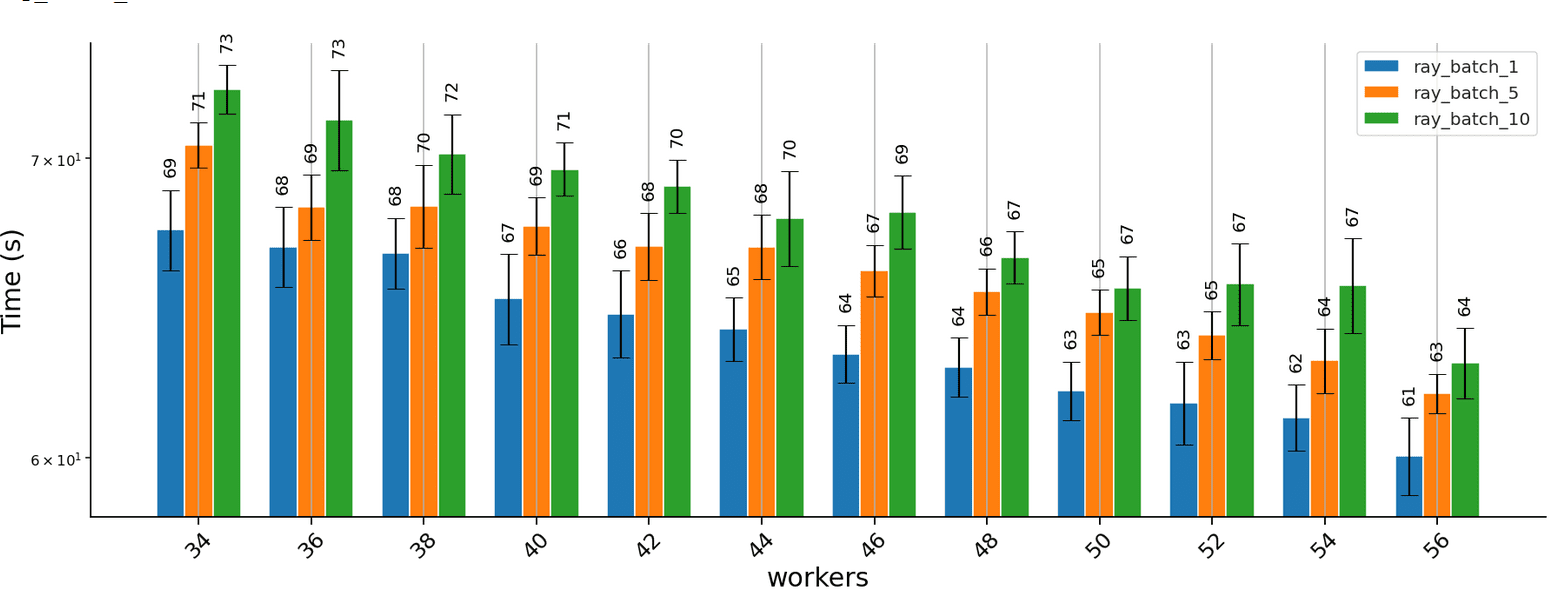
Note that we experimented with different batch sizes. The batch size controls how many predictions are sent to one worker simultaneously. Our primary purpose in doing so was to ensure that the runtime of each explanation task is greater than the overhead of distributing the task; our explainer does not benefit from processing batches since each instance is explained independently of other instances in the batch. While we did not conduct a detailed analysis of why larger batch sizes incur a slight runtime penalty, we suspect that distributing fewer explanation tasks that take longer to run could lead to inefficiencies in resource utilisation (e.g., towards the end there are a few tasks left to execute but some workers are idle).
What to look for going forward with Seldon and Ray
Seldon and Ray make for a great combination. This post demonstrates how easy it was for Alibi to parallelize a given workload on Ray and in the future we look forward to sharing how these toolkits can be used together for everything from model training to serving.
You can also check us both out at Ray Summit. Ray Summit is a FREE Virtual Summit for all things Ray related! Join us to see talks by leading computer scientists, the founders of Anyscale and the Seldon Team.
