A hands on tutorial to train and deploy a Sklearn SpaCy model to process real time Kafka streaming data using Seldon Core
In this post, we will cover how to train and deploy a machine learning model leveraging a scalable stream processing architecture for an automated text prediction use-case. We will be using Sklearn and SpaCy to train an ML model from the Reddit Content Moderation dataset, and we will deploy that model using Seldon Core for real time processing of text data from Kafka real-time streams. This is the content for the talk presented at the NLP Summit 2020.
You can find the full code for this article in the following links:
- Seldon Model Containerization Notebook
- Reddit Dataset Exploratory Data Analysis Notebook
- Kafka Seldon Core Stream Processing Deployment Notebook
Model Training with SpaCy & Sklearn
For this use-case we will be using the Reddit /r/science Content Moderation Dataset. This dataset consists of over 200,000 reddit comments — primarily labelled based on whether the comments have been removed by moderators. We’ll be tasked to train an ML model that is able to predict the comments that would have been removed by reddit moderators.
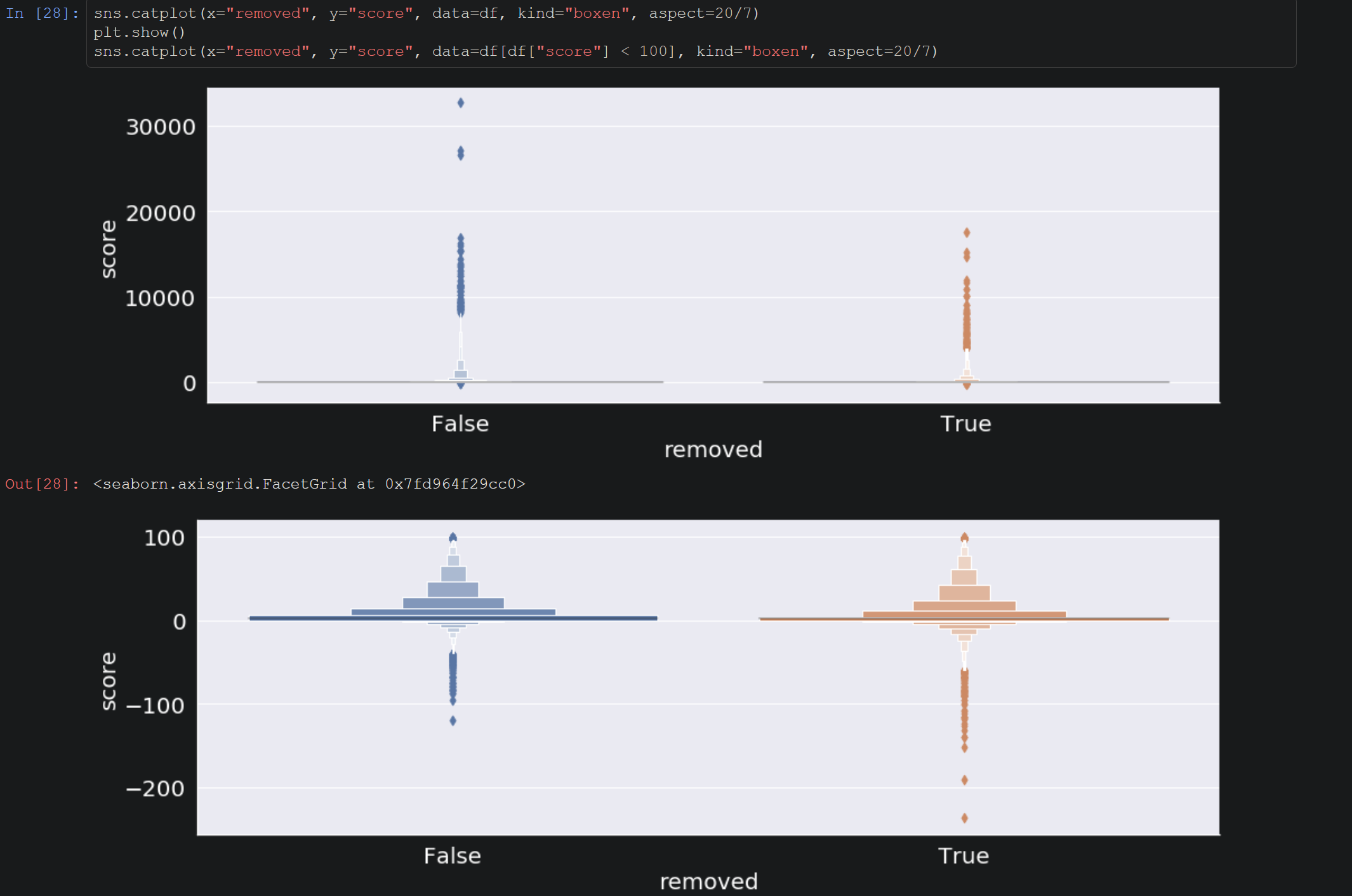
When it comes to building a machine learning model — especially when it is to be deployed to a production system — it is important that principles and best practices are used to ensure its responsible design, development and operation.

You will be able to find best practices and techniques of exploratory data analysis in the model training notebooks — here we cover understanding of the features, data distributions, data imbalances, data cleaning, algorithm performance comparison, tokenization approaches, partial dependency plots, etc.
These techniques enable data scientists and engineers to identify domain specific best practices for the training, deployment and even produciton monitoring of the machine learning models.

Specifically in regards to model training, we will be building the machine learning pipeline using sklearn and SpaCy. As outlined in the image above, we use the following components in the pipeline:
CleanTextTransformer— Cleans input text by removing relevant characters, symbols and repeated phrasesSpacyTokenTransformer— Converts the input text into tokens using SpaCy, and removes relevant tokens such as stopwordsTfidfVectorizer— Converts the tokens into vectors that then can be processed by the modelLogisticRegression— Logistic regression model trained on our current dataset

For a more intuitive flow of how our model will process the data, the image above shows how a text data input instance would be transformed during each of the stages. More specifically, if we receive a phrase, it will be sent through each of the pipeline components until we’re able to receive a prediction.
Once we train our model, we will be able to use the same code that was used for the pipeline, and we will export the artifacts of the models trained using pickle so we can load them when deploying the model.
Model Containerisation with Seldon Core
Once we’ve trained our model, we’re able to use Seldon Core to convert it into a scalable microservice and deploy it to Kubernetes using the Seldon cloud native kubernetes operator. Models deployed with Seldon Core support REST and GRPC interfaces, but since version 1.3 it also supports native kafka interface, which we’ll be using in this article.
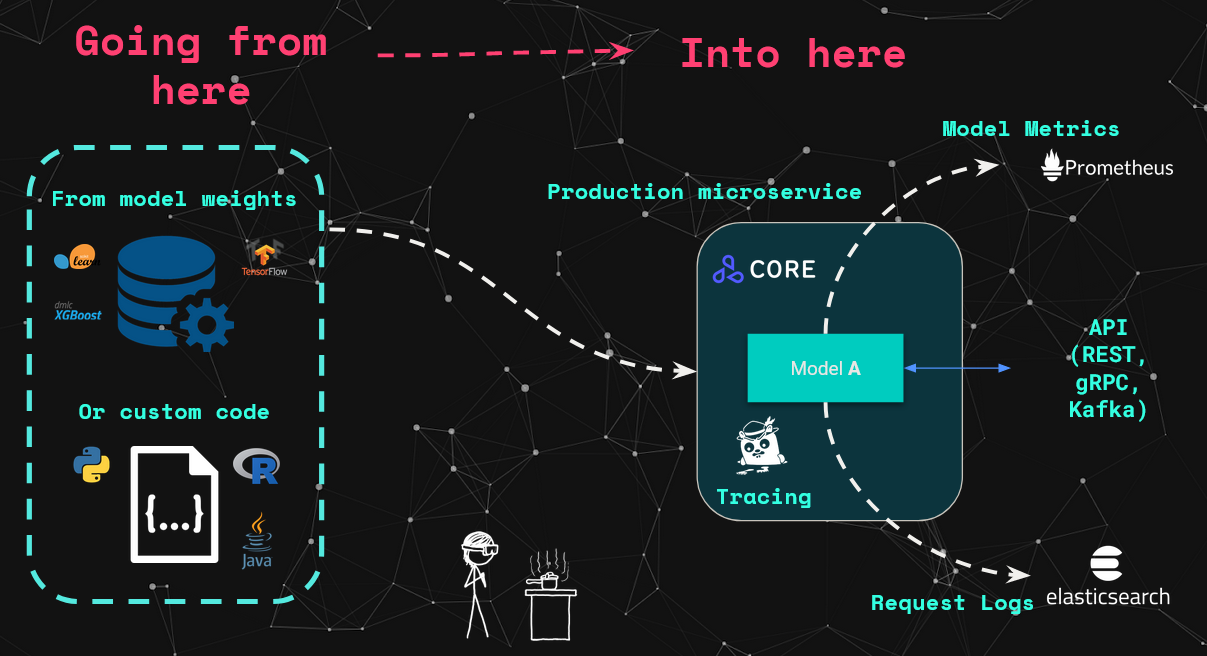
Seldon provides several ways to productionise machine learning models. The most common approach is using one of the existing prepackaged-model servers. In this case however, we will be building our own custom model server by extending the default sklearn pre-packaged server to add SpaCy and its respective English language model.
To containerize our model with Seldon, we will be following the standard Seldon Core workflow using the Python Language wrapper. As shown in the image below, the standard steps required to containerize a model are:
- Create a Python Wrapper Class to expose the model logic
- Add Python dependencies via
requirements.txtfile - Add environment parameters such as protocol, log level, etc
- Optionally add any further dependencies with Dockerfile extension

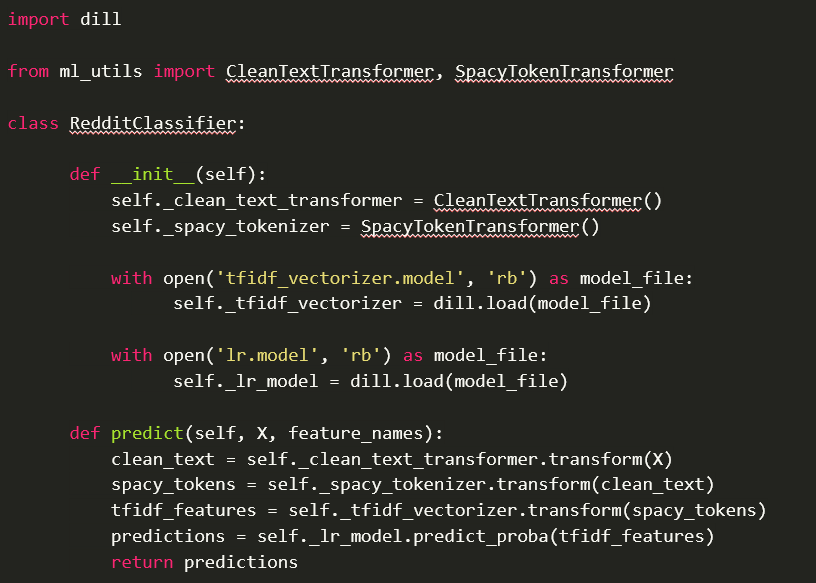
In our case we will just have to define a Python wrapper that will consist of:
- Importing the code for the ML pipeline used in the training section of this article
- An
__init__method that loads the model artifacts - The
predictmethod that gets called every time a request is sent
The code for the wrapper can be found in the image below, or alternatively you can find the full Jupyter notebook to train, containerize and test the Seldon wrapped model.
Once we have the wrapper, we are able to simply run the Seldon utilities using the s2i CLI, namely:
s2i build . seldonio/seldon-core-s2i-python3:1.3.0 nlp-model:0.1
Now we have fully containerised our model as the image nlp-model:0.1 and we will be able to deploy it for stream processing in the next section.
Kafka Stream Processing
Now that we have trained and containerized our model, we’re able to deploy it. Seldon models support REST, GRPC and Kafka protocols — in this example we will be using the latter to support stream processing.
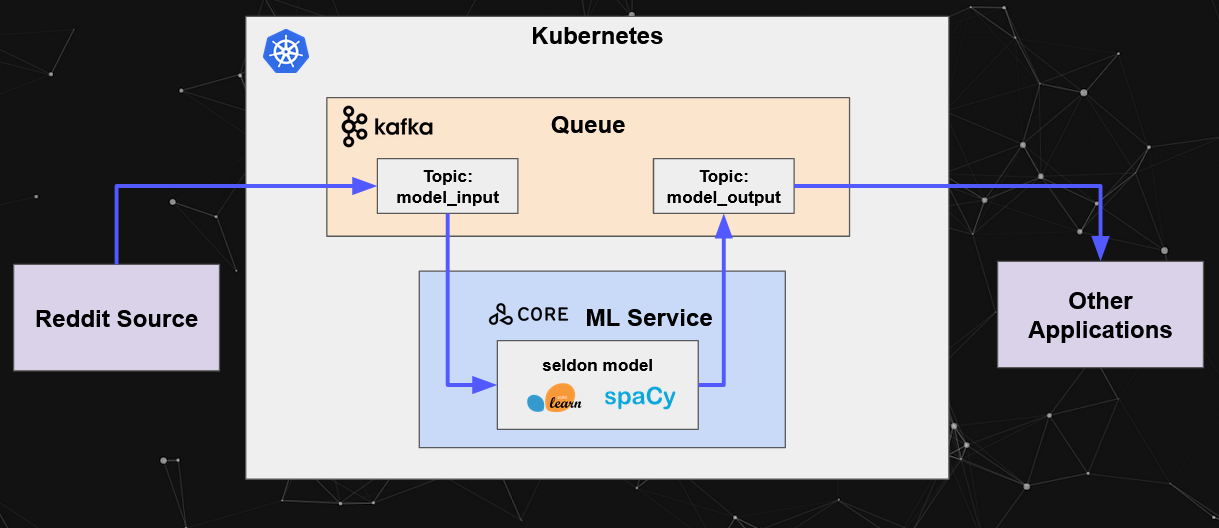
You are able to find the full jupyter notebook for the example including the deployment files as well as the request workflows.
We have the following components:
- Kubernetes Cluster — The Kubernetes cluster where all our components will be deployed to
- Reddit Source — Component that will produce input data in the form of a stream of reddit comments
- Kafka Queue — The Kafka cluster component that will process the streams of data provided by consumers and producers
- Seldon ML Service — Our containerized reddit classifier model deployed using Seldon
- Kafka
model_inputtopic — The input topic where the Reddit Source will produce to, and where our Seldon Model will consume from - Kafka
model_outputtopic — The output topic where other applications can consume from - Other Applications — In the case of our example this is a single consumer application, however this could include any other applications that want to consume from the
model_outputtopic
For simplicity we will skip the steps required to set up the kubernetes cluster — including setting up the Kafka brokers and installing Seldon Core — but you can find the full instructions in the notebook example.
Now we’re able to deploy our model. For this we will just need to define our deployment configuration file following the SeldonDeployment schema:

As you can see in the configuration YAML, the structure contains the following key points:
- The name of the model
name: reddit-kafka - The
graph.name: classifieris the model we will deploy - The
serverType: kafkaenables the deployed microservice with the kafka interface (as opposed to the REST or GRPC protocol) KAFKA_BROKERthe server for the Kafka brokerKAFKA_INPUT_TOPICThe name of the input topic to consume fromKAFKA_OUTPUT_TOPICThe name of the output topic to produce topics
We can now create the model using the kubectl command:
kubectl apply -f sdep_reddit_kafka.yaml
Once our model is created we can now send data into the input topic. We can do so by using the kafka-console-producer.sh utility.

Similarly, we can also listen for the output data that the model produces.

Now when we send the input data to the input topic:
{”data”: {”ndarray”: [”This is an input”]}}
We would consequently see the prediction in the output topic stream:
{“data”:{“names”:[“t:0”,”t:1"],”ndarray”: [[0.6758450844706712, 0.32415491552932885]]},”meta”:{}}
With this we now have a model deployed in a scalable architecture for real time machine learning processing — more specifically, this architecture allows for horizontal and vertical scalability of each of the respective components. Namely, the deployed models can scale to a variable number of replicas, together with autoscaling based on Kubernetes HPA that would horizontally scale based on resource usage. Similarly, Kafka can also scale horizontally through the number of brokers, which enables for large throughputs with low latency. This can be seen more intuitively in the diagram below.
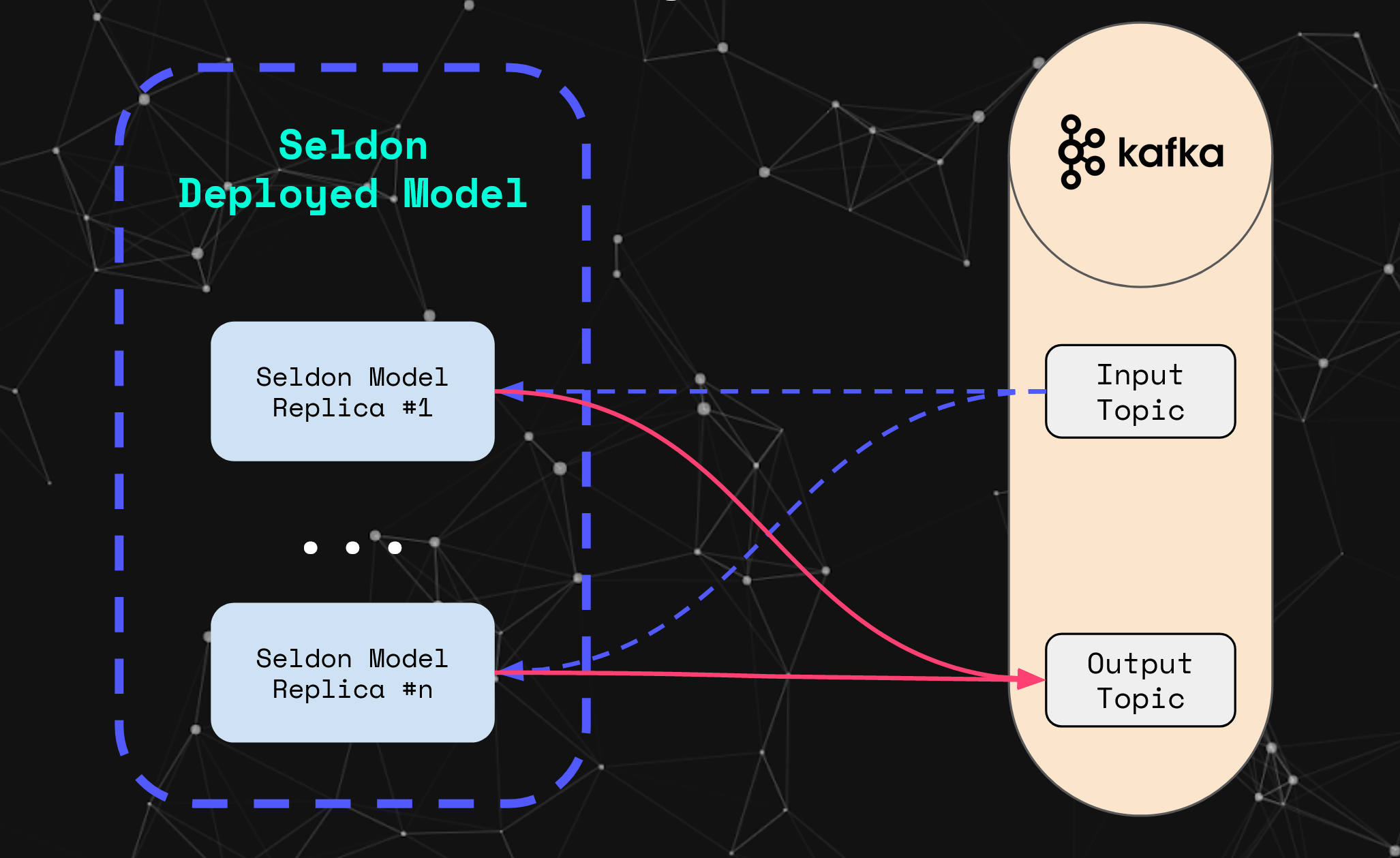
What’s next?
Now that you have the intuition and understanding of the core architectural components, you are now able to delve into the practical details. For this you will be able to access the code and resources in the following links:
- Seldon Model Containerization Notebook
- Reddit Dataset Exploratory Data Analysis Notebook
- Kafka Seldon Core Stream Processing Deployment Notebook
If you are interested in further hands on examples of scalable deployment strategies of machine learning models, you can check out: