As organisations adopt MLOps into their business-as-usual operations, further standardisation is introduced to ensure governance and compliance. As the MLOps strategy matures there is a risk of restricting and slowing down development cycles for the different personas across the machine learning lifecycle.
The Seldon Core 1.8 release aims to tackle this with several new features and functionality. The core highlights of this release include a deeper integration with the Tempo SDK to accelerate data science workflows in MLOps, deeper integration with RClone to enable for artifact download from hundreds of new sources, upgrades to the Alibi Detect server, and new examples showcasing how to use Seldon Core with state of the art hugging-face models leveraging the high performant triton server.
Tempo SDK pre-packaged server
Tempo is a MLOps python SDK that allows packaging custom python servers and orchestration of multiple models from python. The Tempo python SDK allows packaging of the custom code as a conda-pack environment tar ball and Cloudpickle artifacts. It has a Seldon Core runtime which allows Tempo artifacts to be run under Seldon Core.
We can see the power of tempo in the abridged example below – you can find the full example here. Once we have the trained artifact, we can leverage tempo to productionise and interact with our model locally and remotely.
We first define the model, together with the location of the local artifact, and the remote location of the artifact where we want to store it, followed by our custom python logic.
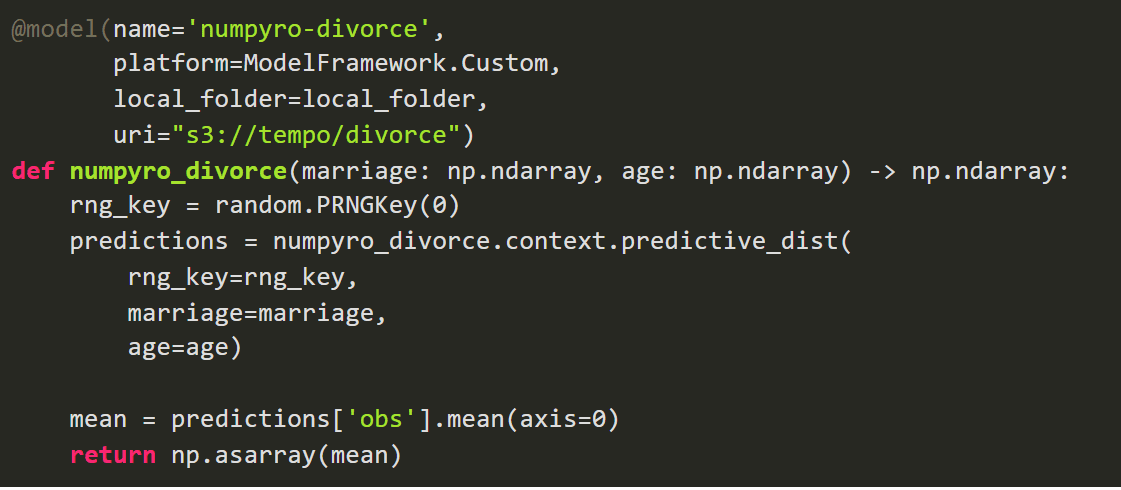
Tempo provides features to test the model using the Seldon Core prepackaged servers locally in Docker, as well as utilities to upload the artifact to remote buckets. For simplicity we will skip that step but you can find the full workflow in the tempo documentation, and we will show how to deploy it straight away in Kubernetes with the command below.

Now our model is deployed in Kubernetes using the Seldon Core Tempo Pre-packaged server, as we can interact with the remote server as if it was a local model.

The full documentation shows how tempo can be used in a declarative way to enable for fully reproducible deployments, as well as to integrate with gitops pipelines.
You can define your own tempo server as per the following YAML file:
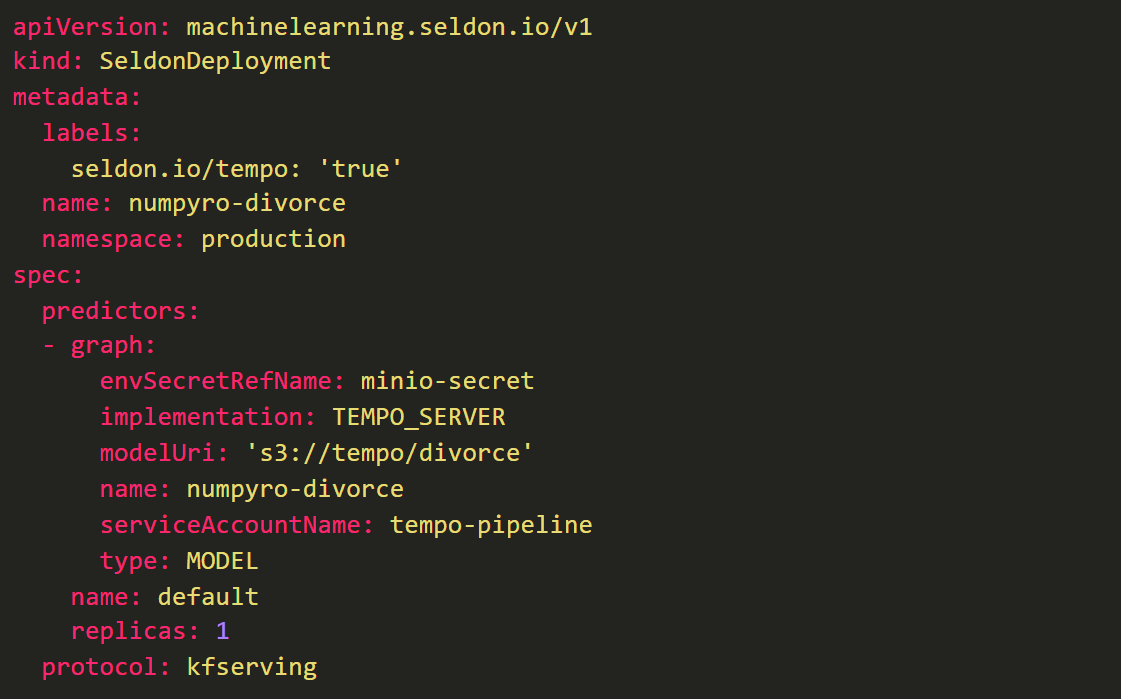
With Tempo, data scientists can be connected to how their models run at inference time. They can test locally with the same container images that will be used at production allowing their models to be ready for production with less delay.
Deeper integration with Rclone
We adopt rclone as our default Storage Initializer. It is sometimes referred as “The Swiss army knife of cloud storage” as it supports roughly 40+ different cloud storage solutions.
The default storage initializer is configured through a following helm value:

with a fallback to the previous solution available and documented in the upgrading section.
Storage initializer image can also be customised per-deployment by setting storageInitializerImage field in the graph definition if required.
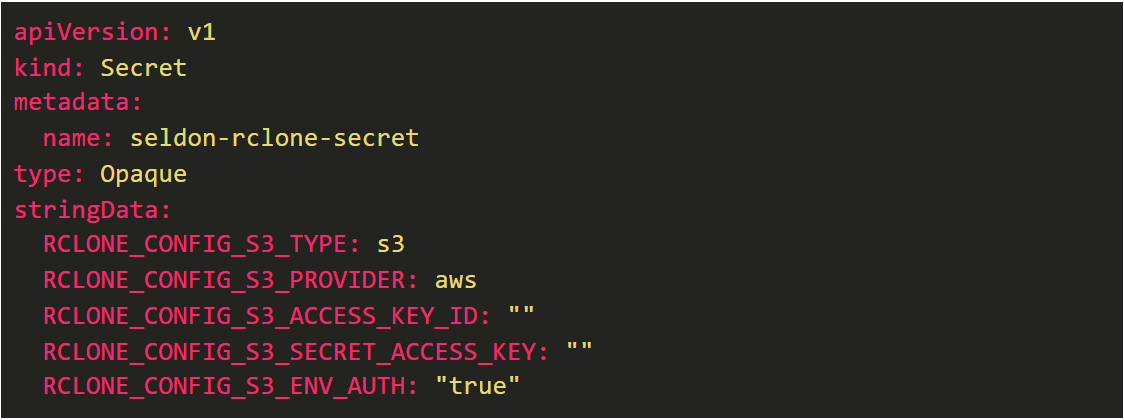
Configuration of rclone-storage-initializer is done with kubernetes Secrets by providing a standard environmental variable that would be accepted by rclone in any other scenario. This enables users to take advantage of the full power of rclone to integrate with every major cloud storage solution out there.
The following example defines s3 endpoint that would work out of the box with node-level IAM roles defined on Amazon EKS or EC2 nodes
 Seldon Core GPT-2 Hugging Face Triton Example
Seldon Core GPT-2 Hugging Face Triton Example
 Seldon Core GPT-2 Hugging Face Triton Example
Seldon Core GPT-2 Hugging Face Triton ExampleWe created an example to show how to leverage Seldon prepackaged Triton server with ONNX Runtime to accelerate model inference when deployed in Kubernetes.
With that goal in mind, we have chosen to use the GPT-2 model, a large transformer-based model developed by OpenAI and made widely accessible through the Hugging Face transformers library.
GPT-2 trained on a huge dataset, with a “simple” objective: predict the next word, given all previous words within a text. Hugging Face gives us easy access to use and export the GPT-2 tokenizer and trained model.
The example notebook walks through the following process:

Exporting the TF GPT-2 model, converting the model to an ONNX model format, deploying it to Kubernetes with Seldon Core (using the Triton prepackaged server with ONNX runtime backend) and interacting with the model through Seldon via KFServing V2 protocol API.
You will also find there an example of the “greedy” approach implementation for a sentence completion using the deployed ONNX GPT2 model.
Link to the Example Jupyter notebook: https://github.com/nadinet/seldon-core/blob/gpt2_notebook_example/examples/triton_gpt2/README.ipynb
Alibi Detect 0.6.2 Integration
With the Seldon Core 1.8.0 release we have updated our Alibi-Detect server to allow running of Alibi-Detect components created with the 0.6.2 release of Alibi-Detect. This brings Seldon Core users the ability to utilize the latest outlier detectors, drift detectors and adversarial detectors made available in recent releases of the library including the ability to use both Tensorflow and PyTorch backends and GPU based detectors as discussed in a recent NVIDIA GTC21 Talk.