To round off our string of recent releases, the team at Seldon is delighted to announce new releases of MLServer and Seldon Core V1.
The new release of MLServer offers a simplified interface, built-in templates and dynamic loading of custom runtimes, as well as a Batch Inference Client for batch processing amongst other cutting-edge features.
Additionally, following the release of Seldon Core V2, we’re still committed to supporting Core V1 and have made some updates to our industry-leading open source MLOps framework. This includes Ambassador v2 and continued Kubeflow support amongst other additional bug fixes and enhancements. Read the full details below.
MLServer 1.2.0 Release
Simplified Interface for Custom Runtimes
Until now, creating a response to be sent back from a custom runtime was often difficult and confusing for new users. MLServer now exposes an alternative simplified interface which can be used to write custom runtimes. This interface lets you specify in the method signature both how you want your request payload to be decoded and how to encode the response back. It can be enabled by decorating your predict() method with the mlserver.codecs.decode_args decorator.
Based on the information provided in the method signature, MLServer will automatically decode the request payload into the different inputs specified as keyword arguments. Under the hood, this is implemented through MLServer’s codecs and content types system.

Built-in Templates for Custom Runtimes
To make it easier to write your own custom runtimes, MLServer now ships with an `mlserver init` command that will generate a templated project. This project will include a skeleton with folders, unit tests, Dockerfiles, etc. for you to fill.

Dynamic Loading of Custom Runtimes
MLServer now lets you load custom runtimes dynamically into a running instance of MLServer. Once you have your custom runtime ready, all you need to do is to move it to your model folder, next to your model-settings.json configuration file.
For example, if we assume a flat model repository where each folder represents a model, you would end up with a folder structure like the one below:

Note that, from the example above, we are assuming that:
- Your custom runtime code lives in the models.py file.
- The implementation field of your model-settings.json configuration file contains the import path of your custom runtime (e.g. models.MyCustomRuntime).
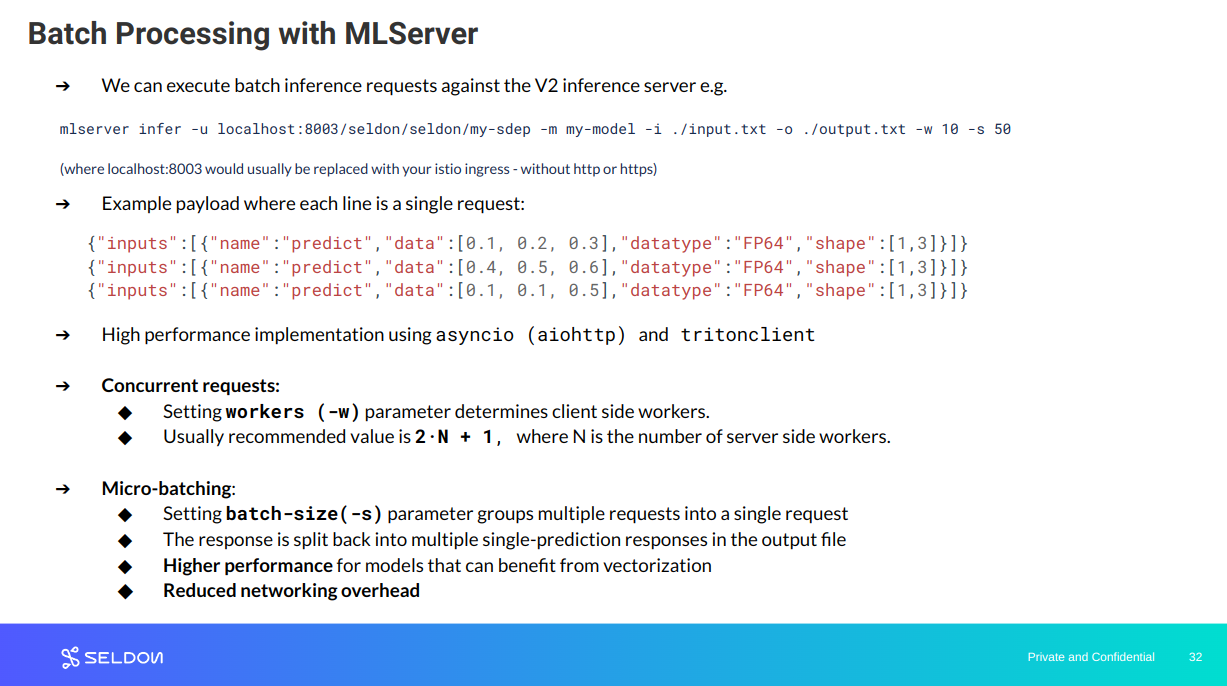
Batch Inference Client
This release of MLServer introduces a new ‘mlserver infer’ command, which lets you run inference over a large batch of input data on the client side. Under the hood, this command will read a large set of inference requests, arrange them in microbatches, orchestrate the request / response lifecycle, and will finally write back the obtained responses.
Parallel Inference Improvements
The 1.2.0 release of MLServer includes a number of fixes around the parallel inference pool focused on improving the architecture to optimize memory usage and reduce latency. These changes include (but are not limited to):
- The main MLServer process won’t load an extra replica of the model anymore. Instead, all computing will occur on the parallel inference pool.
- The worker pool will now ensure that all requests are executed on each worker’s AsyncIO loop, thus optimizing compute time vs IO time.
- Several improvements around logging from the inference workers.
Dropped support for Python 3.7
MLServer has now dropped support for Python 3.7. Going forward, only 3.8, 3.9 and 3.10 will be supported (with 3.8 being used in our official set of images).
Move to UBI Base Images
The official set of MLServer images has now moved to use UBI 9 as a base image. This ensures support to run MLServer in OpenShift clusters, as well as a well-maintained baseline for our images.
Support for MLflow 2.0
In line with MLServer’s close relationship with the MLflow team, this release of MLServer introduces support for the recently released MLflow 2.0. This introduces changes to the drop-in MLflow “scoring protocol” support, in the MLflow runtime for MLServer, to ensure it’s aligned with MLflow 2.0.
MLServer is also shipped as a dependency of MLflow, therefore you can try it out today by installing MLflow as:
| $ pip install mlflow[extras] |
To learn more about how to use MLServer directly from the MLflow CLI, check out the MLflow docs.
Seldon Core 1.15 Release
We are excited to announce the release of 1.15 of Seldon Core our industry leading open source Kubernetes MLOps framework.
Ambassador v2 Support
Seldon Core 1.15 includes updated support for Ambassador edge stack to support V2 Ambassador APIs, which now become the default. The latest Ambassador API is controlled via a set of custom resource definitions rather than the annotations we used before for V1 Ambassador API.
Follow the examples in the docs to get started with Ambassador and Seldon Core. V1 Ambassador API is now deprecated but can be switched on within the Helm install of Seldon Core for legacy customers of Ambassador.
Updated Kubeflow Support
We have recently updated our Kubeflow integration to allow continued support for users of the Kubeflow ecosystem who wish to use Seldon as their inference platform for models built using Kubeflow.
Misc
- Support for SSL_SASL in request logging.
- Continued support and release to Openshift certified images.
- Fix for Kubernetes services to point to each model in an inference graph.
- Move to Flask 2.x for our custom python wrappers.
See the complete changelog for the full list of updates.
Upgrading
Please check upgrading notes before upgrading to the latest version.